

服务器开荒日记(CUDA、cuDNN、nvidia-fabricmaneger安装)—–解决nvcc、驱动正常,但GPU无法正常使用问题
1 安装显卡驱动1.1 禁用nouveau1sudo vim /etc/modprobe.d/blacklist-nouveau.conf
在文件中插入以下内容,将nouveau加入黑名单,默认不开启
12blacklist nouveauoptions nouveau modeset=0
输入以下命令使禁用生效然后重启
12sudo update-initramfs -usudo reboot
重启后验证
1lsmod | grep nouveau
如果回车后无反应,则禁用成功
1.2 安装显卡驱动查询电脑最适合的显卡驱动版本
1ubuntu-drivers devices
安装推荐的显卡驱动,后面标recommended
12sudo apt-get updatesudo apt-get install nvidia-driver-570 #此处数字要对应上面查询到的版本号
安装完成后重启
1sudo reboot
重启后在终端验证
1nvidia-smi
若出现GPU列表,则安装成功
2 安装CUDA下载CUDA),并按照官方提示安装。
12wget https://devel ...
BRIDGE阅读笔记
论文地址:Findings of EMNLP 2020 https://arxiv.org/abs/2012.12627代码:BRIDGE
1 Introduction早期的text2sql任务是在处理单表的问题,然而实际上的数据库是多表、多领域的,早期的方案不能很好的扩展。
针对不同的数据库(DB),近似的自然语言表达生成的 SQL 可能十分不同。因此,跨数据库 text-to-SQL 语义解析器不能仅简单地记住所看到的 SQL 模式,而是必须准确地建模自然语言问题、目标数据库结构以及两者的上下文。
如图中的例子,两个问题问的内容类似,但是生成的sql语句却很不一样。
最先进的跨数据库 text-to-SQL 语义解析器采用以下三个设计原则:
question和schema 的表示是互相关联的;
BERT等预训练模型可以通过增强对自然语言变化的泛化和捕捉长期依赖关系,显著提高解析准确性;
在数据隐私允许的范围内,利用DB content来帮助理解schema,如上图的第二个例子中,“PLVDB”是name字段的值,但是name这个字段在问题中却没有提到,我们需要设计一个方法来 ...
S2SQL阅读笔记
Text-to-SQL任务是Semantic Parsing任务中的一个重要分支。目前最先进的基于图编码器的模型已经被很好的应用于该任务,但是它们并没有对问题的句法进行很好的建模。本文提出了S$^2$SQL,将语法注入到Text-to-SQL解析器的Question-Schema图编码器中,有效地利用了Text-to-SQL解析器中问题的语法依赖信息来提高性能。还利用解耦约束引入不同的关系边缘嵌入,进一步提高了网络的性能。
1 Introduction现阶段,Spider数据集上最有效和最流行的编码器架构是question-schema interaction graph。在此基础上,许多最先进的模型得到了进一步发展,它联合建模自然语言问题和结构化数据库schema信息,并使用一些预定义的关系来划分它们之间的交互关系。然而,我们观察到当前基于图的模型还存在两个主要限制。
句法建模(Syntactic Modelling):句法和语义联合建模是自然语言处理的核心问题。在深度学习范式中,对于以句法为中心特征的任务,如Text-to-SQL任务,应该更好地理解句法的作用。例如,图1显示了基 ...
LGESQL阅读笔记
论文地址:ACL2021 LGESQL: Line Graph Enhanced Text-to-SQL Model with Mixed Local and Non-Local Relations
代码地址:LGESQL
摘要这项工作旨在解决 Text-to-SQL 任务中具有挑战性的异构图(由不同成分组成的图)编码问题。以前的方法通常是以节点为中心,仅仅利用不同的权重矩阵来对边类型进行参数化,这些方法
忽略了嵌入在边的拓扑结构中的丰富语义信息
无法区分每个节点的局部和非局部关系
为此,我们提出了一个 Line Graph Enhanced Text-SQL(LGESQL) 模型来挖掘底层的关系特征,而无需构建元路径。由于line graph的存在,信息不仅通过节点之间的连接,而且通过有向边的拓扑结构更有效地传播。此外,在图的迭代过程中,局部和非局部的关系都被不同程度地整合。我们还设计了一个辅助任务,叫做图修剪(graph pruning),以提高Encoder的辨别能力。在撰写本报告时,我们的框架在跨领域文本到SQL基准的Spider上取得了 state-of-the-art( ...
RAT-SQL阅读笔记
本篇论文研究的问题是:当把自然语言问题翻译成SQL查询,从数据库中搜集数据来回答问题时,现在语义解析模型很难泛化到未见过的数据库模式上。主要的泛化挑战有两个:1、语义parser对数据库关系进行可访问的编码,2、对数据库表列和它们在给定查询问题中的提及进行对齐建模。针对这两个挑战,作者提出了一个统一的框架,基于关系感知的self-attention机制,以解决模式编码、模式链接以及text2sql编码器中的特征表示。作者把这个框架应用到Spider数据集上,取得了57.2% exact match accuracy,在当时实现了SOTA。和BERT一起用,达到了65.6%。此外,最重要的是 模型在对模式链接和对齐的理解上有了质的提高。
论文地址:ACL2020 RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers
代码地址:rat-sql
1、现有的方案现有的方案:由于text2sql是一个seq2seq的任务,utterance translation to sql query,所 ...
IRNet阅读笔记
1. 提出问题Mismatch problem: SQL本身的设计目的是为了准确地向数据库传达执行细节,因此会有与自然言语(后面缩写为NL)表达不一致的地方。比如下例中,FROM、GROUP BY和HAVING等语句,在NL中并没有直接表达出,需要根据问题与表结构才能推断得出。
Lexical problem:Spider数据集跨越不同领域,测试数据的schema中有大量(~35%)的词从未在训练集中出现,这要求模型有更好的泛化性。
2. IRNet的思路2.1 引入中间表示层SemQL为解决Mismatch的问题,设计了一种特定于领域的语言SemQL,作为NL和SQL之间的中间表示。让SemQL和NL之间有更好的映射关系,而SQL可以根据语法规则从SemQL推断生成。
SemQL将GROUPBY,HAVING and FROM clauses都去掉,WHERE和HAVING这些conditions都被统一到Filter关键字。这些操作在之后的推断阶段能够确定性地转换将其转换成SQL。先来举个例子说一下为什么是确定性的呢,例如GROUPBY从句后边跟着的column通常是SELECT ...
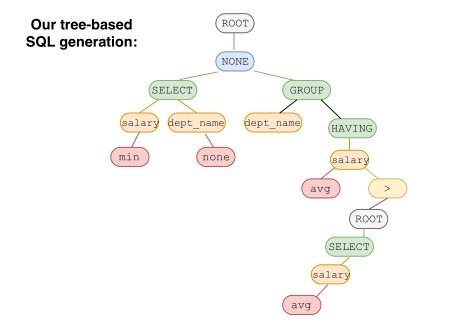
SyntaxSQLNet阅读笔记
1 问题定义这项工作旨在解决复杂的文本到SQL的任务,涉及多个表、SQL子句和嵌套查询。此外,使用单独的数据库进行训练和测试,旨在开发推广到新数据库的模型。
SyntaxSQLNet利用SQL的树结构进行解码
Dataset:使用Spider作为主要数据集,它包含10181个问题,5693个独特的复杂SQL查询,以及200个具有多个表的数据库。
任务和挑战:
该数据集包含大量复杂的SQL标签,与以前的数据集(如WikiSQL)相比,它们涉及更多的表、SQL子句和嵌套查询。为WikiSQL任务开发的现有模型无法处理Spider数据集中那些复杂的SQL查询。
数据集包含200个数据库(∼138个域),不同的数据库用于训练和测试。与大多数先前的语义解析任务(例如,ATIS)不同,该任务需要模型来概括新的、看不见的数据库。
在这个任务中,我们在来自不同数据库的不同复杂SQL查询上训练和测试模型。这旨在确保模型只有在真正理解给定数据库下问题的含义时,才能做出正确的预测,而不是仅仅通过记忆。
2 SyntaxSQLNe ...
HydraNet阅读笔记
以前的所有工作揭示了WikiSQL上NL2SQL的几个主要挑战:
如何融合来自编码器处理的自然语言问题(NL question )和表模式的信息(table schema)。
如何保证解码器处理输出的SQL查询可执行且准确。
如何利用预训练语言模型。
输入表示(Input Representation)给定一个问题q和候选列$c_1, c_2, . . . ,c_k$,表示层的输入变成了每个列的列文本和query文本组成的对(Concat($\phi_{c_i},t_{c_i},c_i$),q),$\phi_{c_i}$表示文本中$c_i$列的类型(分别是string和real),这个信息在X-SQL中是用type embedding来注入模型的,但这里直接作为文本进行输入。这样对于每个列都是BERT标准的sentence pair输入任务;$t_{c_i}$是$c_i$所属表的表名;Concat()是将文本列表连接成一个字符串的函数。
[CLS],x_1,x_2,...,x_m,[SEP],y_1,y_2,...,y_n,[SEP]其中$x_1,x_2,…,x_m$是列表示Co ...
交叉熵、相对熵(KL散度)
信息量任何事件都会承载着一定的信息量,包括已经发生的事件和未发生的事件,只是它们承载的信息量会有所不同。如昨天下雨这个已知事件,因为已经发生,既定事实,那么它的信息量就为0。如明天会下雨这个事件,因为未有发生,那么这个事件的信息量就大。
已知某个事件的信息量是与它发生的概率有关,可以通过如下公式计算信息量:
假设$X$是一个离散型随机变量,其取值集合为$\chi$,概率分布函数$ p ( x ) = Pr(X = x) , x \in \chi $,则定义事件$X=x_0$的信息量为:
I(x_0)=-log(p(x_0))
熵当一个事件发生的概率为$p(x)$,那么它的信息量是$-log(p(x))$。
把这个事件的所有可能性罗列出来,就可以求得该事件信息量的期望,信息量的期望就是熵,所以熵的公式为:
假设事件X共有n种可能,发生$x_i$的概率为$p(x_i)$,那么该事件的熵$H(X)$为:
H(X)=-\sum_{i=1}^np(x_i)log(p(x_i))然而有一类比较特殊的问题,比如投掷硬币只有两种可能,字朝上或花朝上。买彩票只有两种可能,中奖或不中奖。我们称之为 ...
二叉树遍历的递归实现(先序、中序、后序和层次遍历)
由二叉树的定义可知,一棵二叉树由根结点、左子树和右子树三部分组成。因此,只要遍历了这三个部分,就可以实现遍历整个二叉树。若以D、L、R分别表示遍历根结点、左子树、右子树,则二叉树的递归遍历可以有一下四种方式:
1234567/* 二叉树遍历框架 */def traverse(TreeNode root): // 前序遍历 traverse(root.left) // 中序遍历 traverse(root.right) // 后序遍历
1、先序遍历(DLR)口诀:根左右。前序遍历首先访问根结点然后遍历左子树,最后遍历右子树。在遍历左、右子树时,仍然先访问根节点,然后遍历左子树,最后遍历右子树。若二叉树为空则结束返回,否则:(1)访问根结点。(2)前序遍历左子树。(3)前序遍历右子树 。需要注意的是:遍历左右子树时仍然采用前序遍历方法。
举例:
先序遍历结果:ABDEC
注意:已知后序遍历和中序遍历,就能确定先序遍历。
代码:先序遍历:根节点->左子树->右子树
1234567# 前序打印二叉树(递归)def preOrderTraverse ...
X-SQL阅读笔记
X-SQL使用BERT预训练模型的上下文输出增强结构化模式表示,并结合类型信息学习下游任务的新模式表示。
整个体系结构由三层组成:序列编码器,上下文增强模式编码器,输出层。
序列编码器X-SQL在序列编码器中使用类似于BERT结构的模型,但有以下不同:
每个表架构都会附加一个特殊的空列[EMPTY]。
Segment embeddings被type embeddings取代,四种不同的类型分别是:问题,类别列,数值列和特殊的空列。
使用MT-DNN初始化编码器,并且把BERT中的[CLS]标识符改为[CTX],为了强调上下文信息是在那里捕获的,而不是下游任务的表示。
上下文增强模式编码器编码器的输出形式为$h_{[CTX]},h_{q_1},…,h_{q_n},h_{[SEP]},h_{C_{11}},…,h_{[SEP]},h_{C_{21}},…,h_{[SEP]},…,h_{[EMPTY]},h_{[SEP]}$
每个问句中的token编码为$h_{q_i}$,数据库表中第i列的第j个token编码为$h_{C_{ij}}$。上下文增强模式编码器通过$h_{[CTX]}$捕 ...
TypeSQL阅读笔记
该模型基于SQLNet,使用模版填充的方法生成SQL语句。为了更好地建模文本中出现的罕见实体和数字,TypeSQL显式地赋予每个单词类型,使用3个独立模型来预测模版填充值。
创新点:每一个文本中都对其进行类别识别,然后完成作为预先设定的条件放到模型中,这样可以最大限度地融合文本地类型。
输入预处理的类型识别将问句分割n-gram (n取2到6),并搜索数据库表、列。对于匹配成功的部分赋值column类型赋予数字、日期四种类型:INTEGER、FLOAT、DATE、YEAR。对于命名实体,通过搜索FREEBASE,确定5种类型:PERSON,PLACE,COUNTREY,ORGANIZATION,SPORT。这五种类型包括了大部分实体类型。当可以访问数据库内容时,进一步将匹配到的实体标记为具体列名(而不只是column类型)
输入编码输入编码器由两个BI-LSTM组成:BI_LSTM$^{QT}$(Question,Type)和BI_LSTM$^{COL}$(Column)。将问题中的单词及其对应的类型一起输入进BI_LSTM$^{QT}$中,将数据库中的列名输入进BI_LSTM$^{ ...