
Seq2SQL阅读笔记
Seq2SQL
将生成的SQL语句分为三个部分:聚合操作Aggregation(SUM、COUNT、MIN、MAX等);SELECT:选取列;WHERE:查询条件。
首先对query的聚合操作进行分类,并添加一个空操作符表示无聚合。接着指向输入表中对应于SELECT列的一列。最后通过pointer network生成SQL查询语句。
聚合操作
聚合操作的选择取决于问题。采用注意力机制进行分类。$ a_t^{inp}=W^{inp}h_t^{enc} $,代表输入序列的第t个token的注意力得分,权重矩阵与第t个token的输入编码乘积。归一化总的注意力得分,$ B^{inp}=softmax(a^{inp})$。输入表示$k^{agg}$是由归一化分数$B^{inp}$加权的输入编码$h^{enc}$之和。
$a^{agg}$表示聚合操作的得分,如COUNT,MIN,MAX和无聚合操作NULL。通过对输入表示$k^{agg}$应用多层感知机(MLP)来计算$a^{agg}$。
最后通过softmax函数获取预测出的聚合操作$B^{agg}=softmax(a^{agg})$。
SELECT 列
选择列取决于表列和问题。给定列表示和问题表示的列表,选择与问题最匹配的列。
$h_{j,t}^c$表示第j列的第t个encoder状态。将最后一个encoder状态设为$e_j^c$。
$k^{sel}$的构造与$k^{agg}$一样,但使用了不附带条件的权重。
WHERE 子句
使用指针网络训练WHERE子句。但是对于很多查询语句来说,WHERE子句的写法并不唯一,条件可以交换顺序,例如:
SELECT name FROM insurance WHERE age > 18 AND gender =“male”;
$SELECT$ name FROM insurance WHERE gender = “male”AND age > 18;
这可能导致原本正确的输出被判断为错误的。于是作者提出利用强化学习基于查询结果来进行优化。在解码器部分,对可能的输出进行采样,产生若干个SQL语句,每一句表示为y=[y1, y2 … yT],用打分函数对每一句进行打分:
loss是对可能的WHERE子句的负预期回报,$L^{whe}=-E_y{[R(q(y)),q_g]}$。
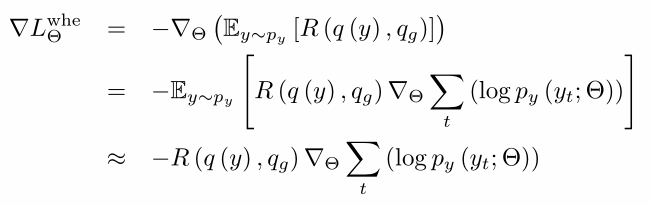
$p_y^{y_t}$表示在时间步t期间选择token$y_t$的概率。
混合目标函数
使用梯度下降法最小化目标函数$L=L^{agg}+L^{sel}+L^{whe}$。总梯度来自预测SELECT列的交叉损失、预测聚合操作的交叉损失以及策略学习的梯度的权重总和。
参考文献
Seq2SQL- Generating Structured Queries from Natural Language using Reinforcement Learning
