
TypeSQL阅读笔记
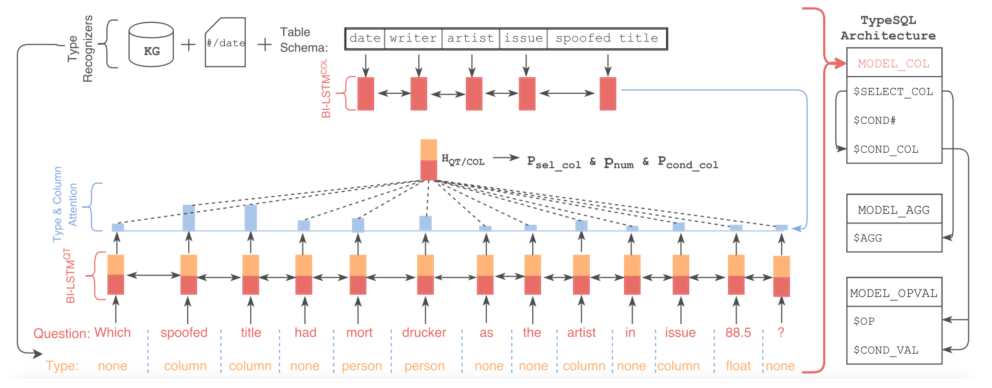
该模型基于SQLNet,使用模版填充的方法生成SQL语句。为了更好地建模文本中出现的罕见实体和数字,TypeSQL显式地赋予每个单词类型,使用3个独立模型来预测模版填充值。
创新点:每一个文本中都对其进行类别识别,然后完成作为预先设定的条件放到模型中,这样可以最大限度地融合文本地类型。
输入预处理的类型识别
将问句分割n-gram (n取2到6),并搜索数据库表、列。对于匹配成功的部分赋值column类型赋予数字、日期四种类型:INTEGER、FLOAT、DATE、YEAR。对于命名实体,通过搜索FREEBASE,确定5种类型:PERSON,PLACE,COUNTREY,ORGANIZATION,SPORT。这五种类型包括了大部分实体类型。当可以访问数据库内容时,进一步将匹配到的实体标记为具体列名(而不只是column类型)
输入编码
输入编码器由两个BI-LSTM组成:BI_LSTM$^{QT}$(Question,Type)和BI_LSTM$^{COL}$(Column)。将问题中的单词及其对应的类型一起输入进BI_LSTM$^{QT}$中,将数据库中的列名输入进BI_LSTM$^{COL}$,那么输出的隐藏状态分别是$H^{QT}$和$H^{COL}$。
对于列名编码,SQLNet是对每一个列名使用BI-LSTM。而TypeSQL首先计算列名中单词嵌入的平均值,之后使用一个BI-LSTM进行编码。这种编码方法将结果提高了1.5%,并将训练时间缩短了一半。尽管列名的顺序并不重要,但这种改进归因于LSTM可以捕获它们的出现和关系。
槽位填充模型
SQLNet为模版中的每一种成分设定了单独的模型;TypeSQL对此进行了改进,对于相似的成分,例如SELECT_COL 和COND_COL以及#COND(条件数),这些信息间有依赖关系,通过合并为单一模型,可以更好建模。TypeSQL使用3个独立模型来预测模版填充,:
- MODEL_COL:SELECT_COL,#COND,COND_COL
- MODEL_AGG:AGG
- MODEL_OPVAL:OP, COND_VAL
其中每个模型中共享BI_LSTM$^{QT}$和BI_LSTM$^{COL}$的参数(总共6个BI-LSTM)。
三个模型都使用SQLNet中提出的column-attention机制来计算问题和类型的加权表示$H_{QT/CLO}$。
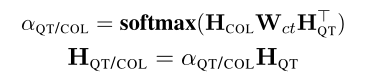
输入矩阵的每一行运用softmax得到$\alpha_{QT/COL}$注意力分数矩阵,$H_{QT/COL}$是问题和类型的加权表示。
MODEL_COL
SELECT_COL:使用$H_{QT/COL}$预测
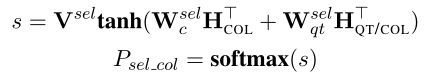
#COND:与SQLNet不同,TypeSQL使用一种更简单的方法计算系统中的条件数,最大条件数设置为4。
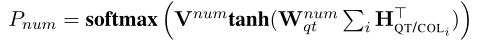
COND_COL:SQLNet经常在COND_COL选择与SELECT_COL相同的列名,为了避免这个问题,使用问题和类型的加权和来预测,该加权和以在SELECT_COL $H_{QT/SCOL}$中选择的列为条件。
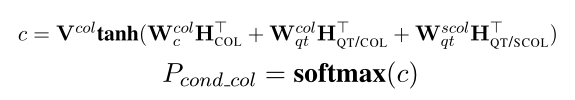
MODEL_AGG
AGG:以在SELECT_COL $H_{QT/SCOL}$中选择的列为条件的问题和类型的加权和来预测。AGG从{NULL,MAX,MIN,COUNT,SUM,AVG}中选择。
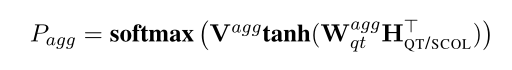
MODEL_OPVAL
OP:对于每个条件列预测,从{=,>,<}选择
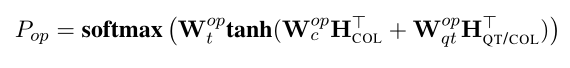
COND_VAL:从问题中为每个预测的COND_COL生成一个子字符串。编码器采用BI-LSTM,使用指针网络计算编码器中下一个token的分布。
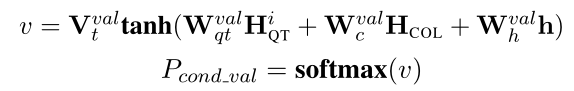
其中h是前一个生成的单词的隐状态
实验结果
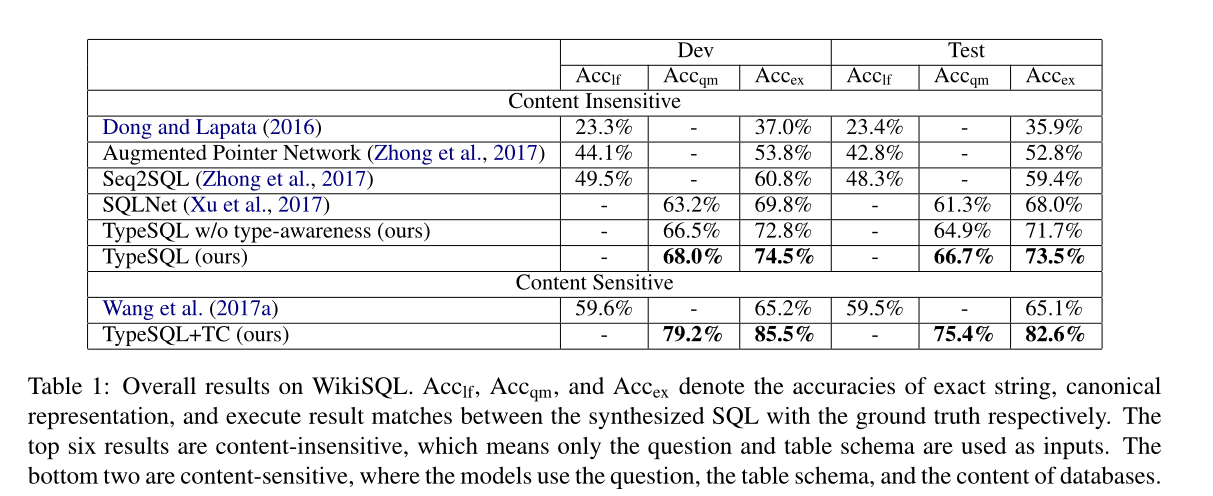
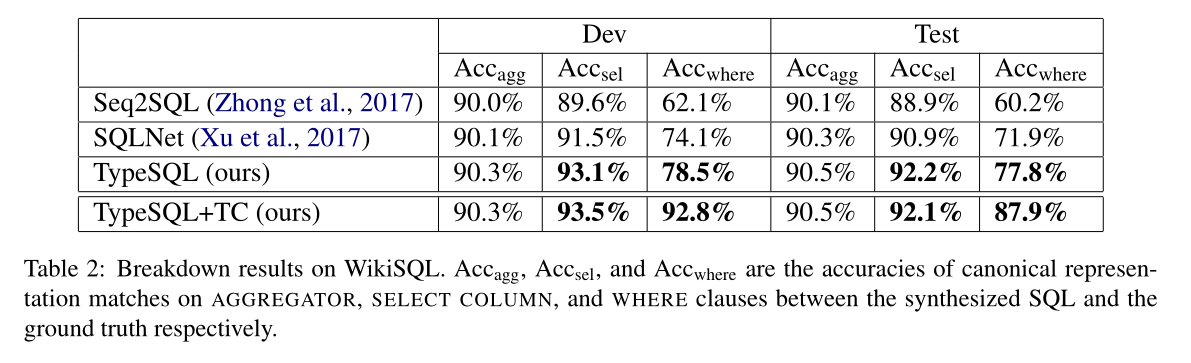
参考文献
TypeSQL: Knowledge-based Type-Aware Neural Text-to-SQL Generation
