X-SQL阅读笔记
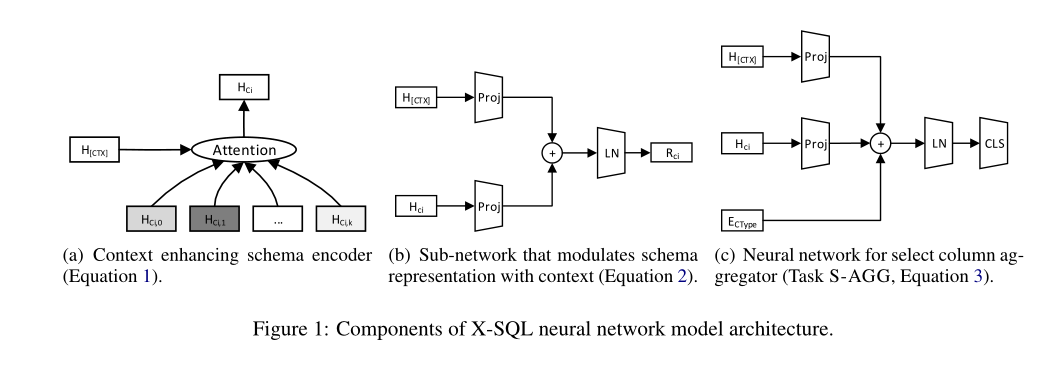
X-SQL使用BERT预训练模型的上下文输出增强结构化模式表示,并结合类型信息学习下游任务的新模式表示。
整个体系结构由三层组成:序列编码器,上下文增强模式编码器,输出层。
序列编码器
X-SQL在序列编码器中使用类似于BERT结构的模型,但有以下不同:
- 每个表架构都会附加一个特殊的空列[EMPTY]。
- Segment embeddings被type embeddings取代,四种不同的类型分别是:问题,类别列,数值列和特殊的空列。
- 使用MT-DNN初始化编码器,并且把BERT中的[CLS]标识符改为[CTX],为了强调上下文信息是在那里捕获的,而不是下游任务的表示。
上下文增强模式编码器
编码器的输出形式为$h_{[CTX]},h_{q_1},…,h_{q_n},h_{[SEP]},h_{C_{11}},…,h_{[SEP]},h_{C_{21}},…,h_{[SEP]},…,h_{[EMPTY]},h_{[SEP]}$
每个问句中的token编码为$h_{q_i}$,数据库表中第i列的第j个token编码为$h_{C_{ij}}$。上下文增强模式编码器通过$h_{[CTX]}$捕捉的全局语境信息俩加强原始编码器的输出,从而为每一列i学习一个新的表示$h_{C_i}$。
其中$\alpha_{it}=SOFTMAX(s_{it})$。对齐模型$s_{it}$表示第i列的第t个token与全局上下文的匹配程度,f使用简单点积。
虽然在序列编码器的输出中捕获到一定程度的上下文,但是由于自注意力机制只集中于某些区域,因此这种影响是有限的。而[CTX]中捕获的全局上下文信息足够多样化,因此被用来补充序列编码器的模式表示。
输出层
该任务被分解为6个子任务,分别是预测W-NUM(条件个数),W-COL(条件对应列,column_index),W-OP(条件运算符,operator_index),W-VAL(条件目标值,condition),S-COL(查询目标列,sel),S-AGG(查询聚合操作,agg),每个子任务预测最终SQL程序的一部分。
首先引入一个任务相关的子网络,它使用上下文$h_{CTX}$调节模式表示$h_{Ci}$。
与公式1不同的是,此计算是针对每个子任务单独完成的,以便更好的将模式表示与每个子任务应关注的自然语言问句中的特定部分对齐。
S-COL:预测SELECT子句的列,是从所有的列中选一个。S-COL只依赖于$r_{Ci}$。
S-AGG:预测SELECT选择的列的聚合器,从可选的6种操作中选一个。为了增强聚合器依赖于所选列类型的直觉(例如MIN聚合器不使用字符串类型的列),显式地将列类型嵌入添加到模型中。
W-NUM:使用$W^{W-NUM}h_{[CTX]}$查找WHERE子句的数量,由于数据集中绝大多数标签的条件都不会超过4个,W-NUM的预测被建模为一个分类任务,直接取[CTX]token的输出加全连接,这个结果需要最先计算得到。建模为四分类,每个标签代表最终SQL的1到4个WHERE子句。无法预测空WHERE子句的情况,空WHERE子句通过K-L散度由W-COL解决。
W-COL:基于W-NUM预测的数量,为WHERE子句选择得分最高的列。
W-OP:为给定的WHERE列选择最可能的操作符,从可选的4种条件操作种选一个。
W-VAL:WHERE子句的预测值。被当做阅读理解任务,因为这个值只能从query获取,所以和阅读理解一样,是一个span prediction任务,即预测value值的start/end position。
训练和推理
在训练期间,优化目标是单个子任务损失的总和。任务S-COL、S-AGG、W-NUM、W-OP和W-VAL使用交叉熵损失,W-COL的损失定义为$D(Q||P^{W-COL})$之间的KL散度。基本事实Q的分布计算如下:
- 如果没有WHERE子句,$Q_{[EMPTY]}$接收特殊列[EMPTY]的概率为1。
- 对于n≥1个WHERE子句,每个WHERE列接收概率为$\frac{1}{n}$。
如果得分最高的列是特殊列[EMPTY],我们忽略W-NUM的输出并返回空的WHERE子句。否则,选择前W-NUM个W-COL中的非[EMPTY]列。
实验结果
使用WikiSQL数据集的默认train/dev/test拆分。评价标准是逻辑形式准确性(SQL查询的精确匹配)和执行准确性(预测的SQL查询导致正确答案的比率)。逻辑形式准确性是我们在训练期间优化的指标。
- 不同方法在推理期间应用和不应用执行指导(EG)的结果
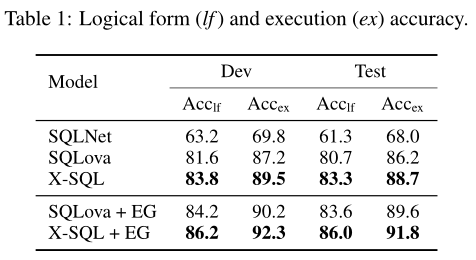
在没有EG的情况下,X-SQL在逻辑形式准确性方面提供了2.6%的绝对改进(83.3对80.7),在测试集上执行准确性方面提供了2.5%的改进。
即使有了EG,X-SQL在逻辑形式精度上还是好了2.4%,在执行精度上也是好了2.2%。值得注意的是,X-SQL+EG是第一个在测试集上超过90%准确率的模型。
根据Hwang等人(2019年)的说法,对于开发集,人类性能估计为88.2%。XSQL是第一个在没有执行指导的帮助下,比人类表现更好的模型。
- 不同方法的每个子任务的准确性
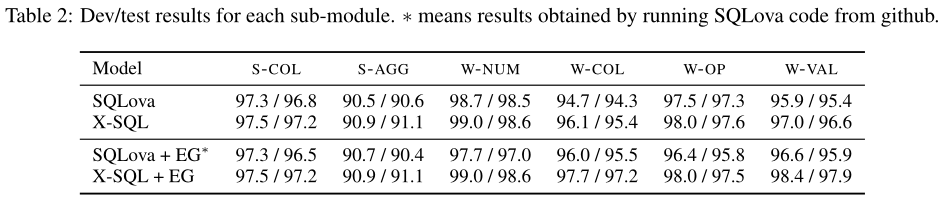
任务W-COL在没有EG的情况下显示了1.1%的绝对增益,在有EG的情况下显示了1.7%的绝对增益。将此归因于我们使用KL散度将where列预测形式化为列表排序问题的新方法。
另一个显著的改进是W-VAL任务,没有EG时的绝对增益为1.2%,有EG时的绝对增益为2.0%。这部分是由于列集预测(即W-COL)的改进,因为值生成高度依赖于where子句的预测列集。
总结
提出一个新的模型X-SQL,展示了它在WikiSQL任务上的出色性能,并在所有指标上实现了新的最先进水平。虽然围绕损失目标的贡献可能受到WikiSQL使用的特定SQL语法的限制,但如何利用上下文信息以及如何使用模式类型可以立即应用于涉及结构化数据的预训练语言模型的其他任务。未来的工作包括试验更复杂的数据集,如Spider(Yuetal.,2018b)。
参考文献
X-SQL:reinforceschemarepresentationwithcontext-MicrosoftResearch