HydraNet阅读笔记
以前的所有工作揭示了WikiSQL上NL2SQL的几个主要挑战:
- 如何融合来自编码器处理的自然语言问题(NL question )和表模式的信息(table schema)。
- 如何保证解码器处理输出的SQL查询可执行且准确。
- 如何利用预训练语言模型。
输入表示(Input Representation)
给定一个问题q和候选列$c_1, c_2, . . . ,c_k$,表示层的输入变成了每个列的列文本和query文本组成的对(Concat($\phi_{c_i},t_{c_i},c_i$),q),$\phi_{c_i}$表示文本中$c_i$列的类型(分别是string和real),这个信息在X-SQL中是用type embedding来注入模型的,但这里直接作为文本进行输入。这样对于每个列都是BERT标准的sentence pair输入任务;$t_{c_i}$是$c_i$所属表的表名;Concat()是将文本列表连接成一个字符串的函数。
其中$x_1,x_2,…,x_m$是列表示Concat的token,$y_1,y_2,…,y_n$是问题q的token。
SQL查询表示和任务
在本文中,考虑没有嵌套结构的SQL查询,形式如下:
”sql”:{
“select”: [(agg1,scol1),(agg2,scol2),…]
“from”: [table1,table2,…]
“where”: [(wcol1,op1,value1),(wcol2,op2,value2),…]
}
将上述SQL查询中的对象分为两类:
- 与具体列有关的任务,如W-COL,W-OP,W-VAL。这些任务被建模成sentence pair输入的分类任务和阅读理解任务;
- 与具体列无关的任务,如W-NUM和S-NUM。在X-SQL里由于一次输入了所有列,这俩可以一次性得到的;但由于HydraNet把列打散了,要么通过设定阈值来选取,要么需要对所有列的结果加权来得到。
对于第一种类型,使用$h_{[CLS]},h_1^{c_i},…,h_m^{c_i},h_{[SEP]},h_1^q,…,h_n^q,h_{[SEP]}$表示base模型的输出序列嵌入。
- 对于聚合算子$a_j,令P(a_{j}|c_{i},q)=\operatorname{softmax}(W^{agg}[j,:] \cdot h_{[CLS]})$。在训练期间,屏蔽掉不在聚合算子训练任务的 select 子句中的列。
- 对于条件运算符$o_j,令P(o_j|c_{i},q)=\operatorname{softmax}(W^{op}[j,:]\cdot h_{[CLS]})$。在训练期间,屏蔽了条件运算符训练任务中不在 where 子句中的列。
- 对于where 子句中value开始和结束的索引,令$P(y_{j}=\operatorname{start}|c_{i},q)=\operatorname{softmax}(W^{start} \cdot h_j^q)$和$P(y_{j}=\operatorname{end}|c_{i},q)=\operatorname{softmax}(W^{\operatorname{end}}\cdot h_{j}^{q})$。在训练期间,对于不在 where 子句中的列,开始和结束索引设置为 0。
对于没有关联的全局对象,$P(z|q)=\sum_{c_{i}}P(z|c_{i},q)P(c_{i}|q)$。将$P(z|c_{i},q)$看做句子对分类,$P(c_{i},q)$看做列$c_i$和问题$q$之间的相似性。
- 对于select子句的数量$n_s$,$P(n_s|q)=\sum_{c_{i}}P(n_s|c_{i},q)P(c_{i}|q)$
- 对于where子句的数量$n_w$,$P(n_w|q)=\sum_{c_{i}}P(n_w|c_{i},q)P(c_{i}|q)$
列排序
对于每个问题q,$S_q$是SELECT子句中的列集,$W_q$是WHERE子句中的列集。$R_q=S_q \bigcup W_q$表示SQL查询中的相关列集。将候选列集表示为$C_q={c_1,c_2,…,c_k}$。
排序任务分为三个:
- SELECT-Rank:根据q的SELECT子句是否包含$c_i,即c_i \in S_q$,对$c_i \in C_q$进行排序。
- WHERE-Rank:根据q的WHERE子句是否包含$c_i,即c_i \in W_q$,对$c_i \in C_q$进行排序。
- Relevance-Rank:根据q的SQL查询是否包含$c_i$,即$c_i \in R_q$,对$c_i \in C_q$进行排序。
$P(c_{i}\in S_{q}|q)=\operatorname{sigmoid}(w_{sc}\cdot h_{[CLS]})$,$P(c_{i}\in W_{q}|q)=\operatorname{sigmoid}(w_{wc}\cdot h_{[CLS]})$,$P(c_{i}\in R_{q}|q)=\operatorname{sigmoid}(w_{rc}\cdot h_{[CLS]})$分别表示SELECT-Rank,WHERE-Rank,Relevance-Rank的排序分数。通过保留前$n_s,n_w$个列来构成SELECT子句和WHERE子句。
推理
在推理过程中,首先从模型输出中获得每个单独任务的预测标签。然后按照以下步骤构造预测的SQL查询:
- 计算每个对的所有子任务结果;
- 分别通过等式 1 和 2 获得预测的W-NUM和SEL-NUM;
- 对每个对针对select进行排序,选出得分最高的SEL-NUM个列及其相关的agg作为条件;
- 对每个对针对where进行排序,选出得分最高的W-NUM个列及其相关的val、op作为条件;
- 对于多表情况,综合多张表的前四步结果。
实验结果
展示 HydraNet 在 WikiSQL 数据集上的结果,并将其与其他最先进的方法进行比较。
- 应用和不应用执行引导解码 (EG) 的不同方法的结果。

- 使用 BERT-Large-Uncased 的 HydraNet 明显优于使用相同基本模型的 SQLova,甚至与使用 MT-DNN 作为基本模型的 X-SQL 一样好。MT-DNN 已证明明显优于 BERT-Large-Uncased(Liu 等人,2019a),并且在 GLUE Benchmark 3 上的得分与 RoBERTa 相似。这意味着 HydraNet 更擅长利用预训练的 Transformer 模型。
- 通过比较开发集和测试集的准确性,发现HydraNet也表现出更好的泛化能力,这是因为它只在基本模型的输出中添加了全连接层,这比X-SQL和SQLova的输出架构更简单且参数更少。
- 应用和不应用 EG 的每个任务的准确性。
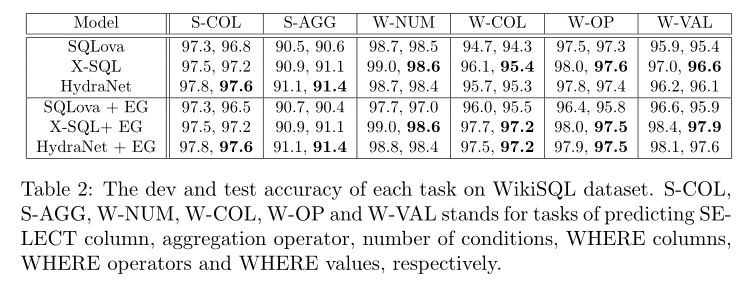
在测试集上,HydraNet 的 SELECT 列预测准确率最高,WHERE 列预测准确率与 X-SQL 的 几乎相同。这证明了列-问题对排序机制在列比较和列选择方面与全列的问题排序机制是一样好的。
总结
本文研究了如何在WikiSQL任务中利用BERT等预先训练好的语言模型。将文本到sql表述为一个列式混合排序问题,并提出了一个名为HydraNet的整洁网络结构,它最好地利用了预先训练的语言模型。提出的模型结构简单。
在SELECT子句预测上HydraNet的准确率最高,在WHERE子句预测上X-SQL的准确率最高。