
SyntaxSQLNet阅读笔记
1 问题定义
这项工作旨在解决复杂的文本到SQL的任务,涉及多个表、SQL子句和嵌套查询。此外,使用单独的数据库进行训练和测试,旨在开发推广到新数据库的模型。
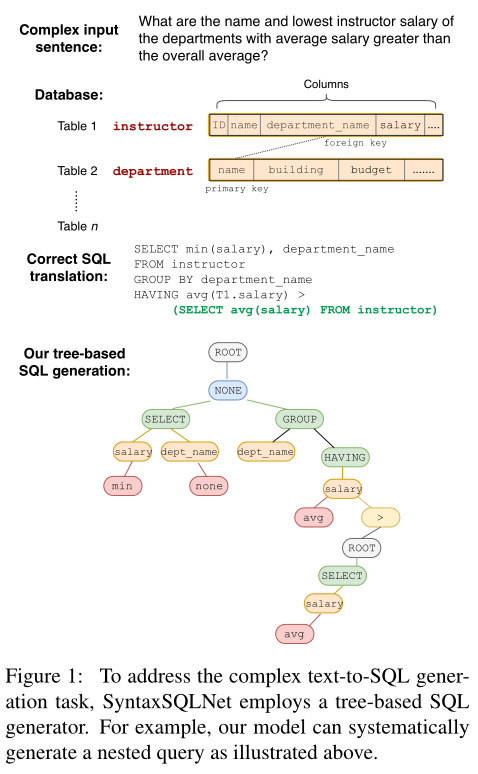
SyntaxSQLNet利用SQL的树结构进行解码
Dataset:使用Spider作为主要数据集,它包含10181个问题,5693个独特的复杂SQL查询,以及200个具有多个表的数据库。
任务和挑战:
- 该数据集包含大量复杂的SQL标签,与以前的数据集(如WikiSQL)相比,它们涉及更多的表、SQL子句和嵌套查询。为WikiSQL任务开发的现有模型无法处理Spider数据集中那些复杂的SQL查询。
- 数据集包含200个数据库(∼138个域),不同的数据库用于训练和测试。与大多数先前的语义解析任务(例如,ATIS)不同,该任务需要模型来概括新的、看不见的数据库。
在这个任务中,我们在来自不同数据库的不同复杂SQL查询上训练和测试模型。这旨在确保模型只有在真正理解给定数据库下问题的含义时,才能做出正确的预测,而不是仅仅通过记忆。
2 SyntaxSQLNet的思路
将解码器构造为递归模块的集合。为了充分利用SQL查询的良好定义的结构,使用SQL特定的语法来指导解码过程。
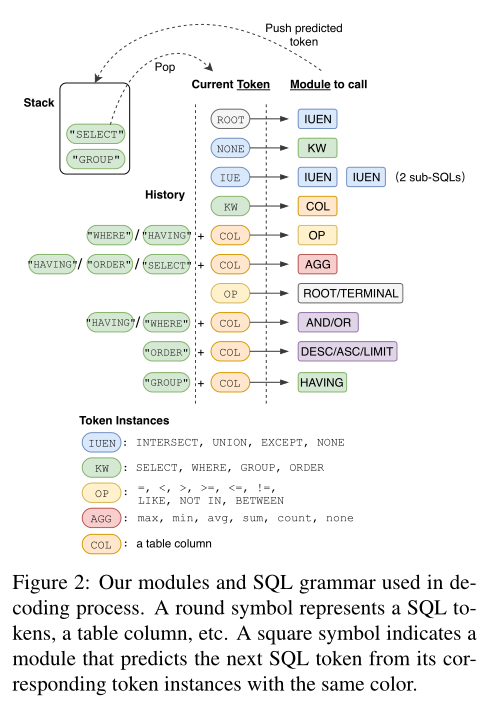
图2是在解码过程中使用的模块和 SQL 语法。圆形符号表示一个 SQL 关键字,如SELECT、WHERE、表列等。方形符号表示一个模块,该模块从其对应的具有相同颜色的令牌实例中预测下一个 SQL 关键字。
2.1 模块概述
SyntaxSQLNet模型将SQL语句的预测分解为9个模块,解码时由预定义的SQL语法确定这9个模块的调用顺序,从而引入结构信息。树的生成顺序为深度优先。分解出的9个模块有:
- IUEN模块:预测INTERCEPT、UNION、EXCEPT、NONE(是否调用自身来生成嵌套查询)。
- KW模块:预测WHERE、GROUP BY、ORDER BY、SELECT关键字。spider数据集中的所有查询都有 SELECT。
- COL模块:预测列名。
- OP模块:预测>、<、=、>=、<=、!=、LIKE、NOT IN、IN、BETWEEN等运算符。
- AGG模块:预测MAX、MIN、SUM、COUNT、AVG 和 NONE 等聚合函数。
- Root/Terminal模块:预测子查询或终结符。
- AND/OR模块:预测条件表达式间的关系(AND、OR)
- DESC/ASC/LIMIT模块:预测与ORDER BY相关的关键字。只有在预测有ORDER BY才会调用。
- HAVING模块:预测与GROUP BY相关的Having从句。只有在预测有GROUP BY才会调用。
2.2 SQL语法
在解码过程中,给定当前的SQL关键字和SQL历史(我们为了得到当前关键字而浏览的token),确定要调用哪个模块,并预测要生成的下一个SQL标记。
为了在解码时调用HAVING和OP等模块,不仅要检查当前token实例的类型,还要查看之前解码的SQL token的类型对于HAVING模块是否为GROUP,对于OP模块是否为WHERE或HAVING。
2.3 输入Encoder
每个模块的输入包括三种类型的信息:问题、表模式和当前SQL解码历史路径。通过BiLSTM对问题进行编码。
2.3.1 Table-Aware列表示
为了在测试中对新的数据库进行泛化,必须使模型学会从数据库模式中获取必要的信息,因此同时使用表名和列名来构建列嵌入。
- 首先对表名进行embedding,得到每个表的表名向量。
- 对每个列名进行embedding,得到初始的列名向量。
- 将表名向量与列的类型信息(字符串或数字,主/外键)相连接产生列向量。
- 用一个BiLSTM连接数据库中的所有列,以获得高级列嵌入。
我们的编码方案可以有效地捕获数据库模式中的全局(表名)和本地(列名和类型)信息,以在给定数据库的上下文中理解问题。
2.3.2 SQL解码历史
通过传递 SQL 历史记录,每个模块在递归 SQL 生成过程中每次调用它时都能够根据历史记录预测不同的输出。SQL 历史记录可以提高每个模块在长而复杂的查询上的性能,因为历史记录有助于模型捕获子句之间的关系。
2.4 模块详情
与SQLNet类似,为每个模块采用了基于草图的方法,以避免在基于 seq2seq 的 SQL 生成模型中发生的顺序问题。
给定一个embedding$H_2$,计算embbeding$H_1$的条件嵌入$H_{1/2}$。
从给定的分数矩阵 U 中得到概率分布的公式为:
将LSTM在问题嵌入、路径历史和列嵌入上的隐藏状态分别表示为$H_Q、H_{HS}$和$H_{COL}$。将LSTM在多重关键词嵌入和关键词嵌入上的隐藏状态分别表示为$H_{MKW}$和$H_{KW}$。每个模块的输出计算如下:
IUEN模块:从{INTERCEPT, UNION, EXCEPT, NONE} 中选择一个调用,计算公式为:
KW模块:首先预测SQL查询中的关键词数量,然后从{SELECT, WHERE, GROUP BY, ORDER BY}中预测关键词。
COL模块:首先预测 SQL 查询中的列数,然后预测要使用哪些列。
OP模块:对于 WHERE 子句中来自 COL 模块的每个预测列,首先预测其上的运算符数量,然后从 {=, >, <, >=, <=, ! = , LIKE, NOTIN, IN, BETWEEN}中选择操作符。$H_{CS}$表示COL模块一个预测列的嵌入。
AGG模块:对于 SELECT 子句中 COL 模块中的每个预测列,首先预测其上的聚合器数量,然后从 {MAX, MIN, SUM, COUNT, AVG, NONE} 预测要使用哪些聚合器
Root/Terminal模块:对于 WHERE 子句中 COL 模块中的每个预测列,首先调用 OP 模块,然后预测下一个解码步骤是“ROOT”节点还是值终端节点。
AND/OR模块:对于从COL模块预测的每一个条件列(当列数大于1),预测{AND,OR}连接词。
DESC/ASC/LIMIT:对于ORDER BY子句中COL模块的每个预测列,从{DESC,ASC,DESC LIMIT,ASC LIMIT}进行预测关键词。
HAVING模块:对于GROUP BY子句中的COL模块中的每个预测列,预测它是否在HAVING BY子句中
2.5 递归SQL生成
SQL生成过程是一个递归地激活不同模块的过程。如图2所示,采用一个堆栈来组织解码过程。在每个解码步骤中,从堆栈中弹出一个SQL关键词,并根据语法调用一个模块来预测下一个关键词,然后将预测的关键词推入堆栈。解码过程一直持续到堆栈为空。
在第一个解码步骤中只用ROOT来初始化一个堆栈。在下一步,堆栈会弹出ROOT。如图2所示,ROOT激活IUEN模块来预测是否有EXCEPT、INTERSECT或UNION。如果是这样,下一步就会有两个子查询被生成。
如果模型预测为NONE,它将被推入堆栈。堆栈在下一步弹出NONE。例如,在图2中,当前弹出的标记是SELECT,它是一个关键字(KW)类型的实例。它调用COL模块来预测一个列名,该列名将被推到堆栈中。
3 数据增强
该工作提出了一种针对text2sql任务的数据增强方法,生成跨领域、更多样的训练数据。通过该技术,模型的精确匹配率提高了7.5%。
具体做法为:
- 对SPIDER中的每条数据,将值和列名信息除去,得到一个模板;对处理后的SQL模版进行聚类,通过规则去除比较简单的模板,并依据模板出现的频率,挑选50个复杂SQL模板;人工核对SQL-问句对,确保SQL模板中每个槽在问句中都有对应类型的信息。
- 得到一一对应的模板后,应用于WikiSQL数据库:首先随机挑选10个模板,然后从库中选择相同类型的列,最后用列名和值填充SQL模板和问句模板。通过该方法,作者最终在18000的WikiSQL数据库上得到了新的98000组训练数据,同时在训练的时候也利用了WikiSQL数据集原有的训练数据。
参考文献
SyntaxSQLNet: Syntax Tree Networks for Complex and Cross-DomainText-to-SQL Task
