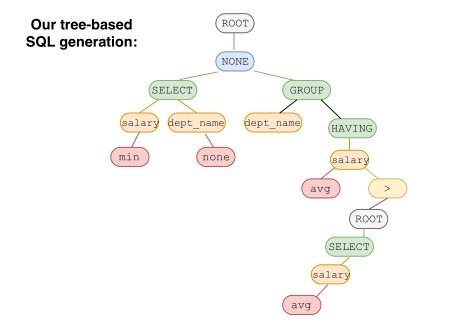
IRNet阅读笔记
1. 提出问题
Mismatch problem: SQL本身的设计目的是为了准确地向数据库传达执行细节,因此会有与自然言语(后面缩写为NL)表达不一致的地方。比如下例中,FROM、GROUP BY和HAVING等语句,在NL中并没有直接表达出,需要根据问题与表结构才能推断得出。

Lexical problem:Spider数据集跨越不同领域,测试数据的schema中有大量(~35%)的词从未在训练集中出现,这要求模型有更好的泛化性。
2. IRNet的思路
2.1 引入中间表示层SemQL
为解决Mismatch的问题,设计了一种特定于领域的语言SemQL,作为NL和SQL之间的中间表示。让SemQL和NL之间有更好的映射关系,而SQL可以根据语法规则从SemQL推断生成。
SemQL将GROUPBY,HAVING and FROM clauses都去掉,WHERE和HAVING这些conditions都被统一到Filter关键字。这些操作在之后的推断阶段能够确定性地转换将其转换成SQL。先来举个例子说一下为什么是确定性的呢,例如GROUPBY从句后边跟着的column通常是SELECT从句后边的column 或者 该column是表的主键,在这个表中一个聚合函数被应用到这个表的一个column中。每个C都有一个T对应,这样能够有效的防止多个表中有相同的column name。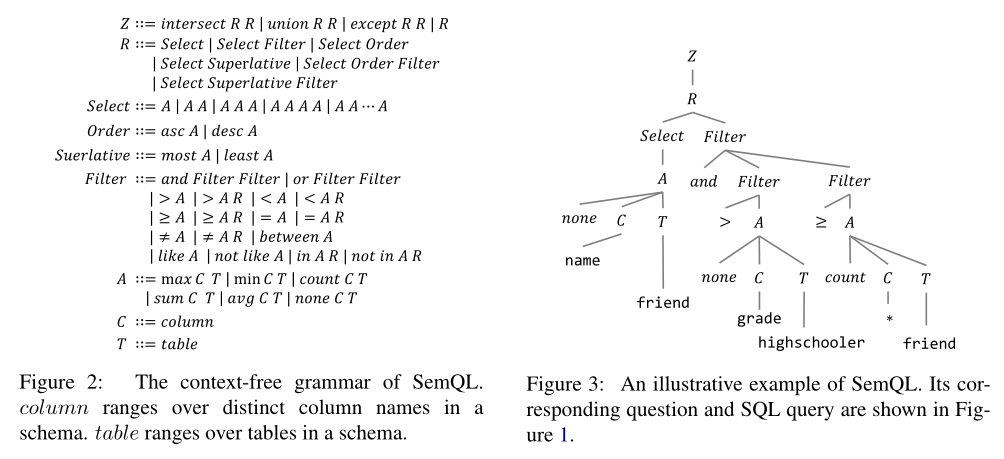
上图左边是SemQL的语法结构,Z是根节点,R表示一个SQL单句,如”Select Filter“表示当前的SQL单句里包含有SELECT和WHERE两个语句。Order和Superlative与SQL中的ORDER BY对应,其中Superlative可以映射到ORDER BY + LIMIT。比如成绩最高的5个人,最后在SQL中表达为ORDER BY grade desc LIMIT 5。
上图右边是从图1中NL对应的SemQL。
2.2 模式链接Schema Linking
任务目标:识别问题中提到的columns 和 tables,并且根据问题中提及的方式给每个columns赋予不同的类型(Table、Column、Value)。
识别的方式为字符串匹配:用n-grams枚举出所有可能的单词组合,其中n的取值为1~6。如果ngram可以完全匹配或者部分匹配上某个Column的名称,则识别为Column。用同样的方法识别Table。如果某个n-grams同时被识别为Column和Table,那么默认它是一个Column。识别完成后,Questions会被分成各个Span(分段),每个Span会进一步标识一个具体的类别,如Column、Table、None等。对于被识别为列的span,如果它们与模式中的列名完全匹配,为这些列分配 EXACT MATCH类型,否则分配 PARTIAL MATCH类型。
Value的识别:论文中没有用到DB Content,而是使用ConceptNet。如果n-gram开始和结束都是引号,则默认为database中的value。把Value Span到ConceptNet中进行查询,找到对应的Concept再来跟Column Name对比,如果能匹配上,就能确定Value和Column之间的对应关系。比如,“Masters”是一种“Degree”,如果Column中有“Degree”,那么“Masters”就会被认为是Degree Column的一个枚举值。
这里留下一个改进的空间:使用DB Content可以提升Column和Value的识别能力。而在实际应用中,不少情况下DB Content是可以获取的,只是有一定的资源开销。
2.3 模型
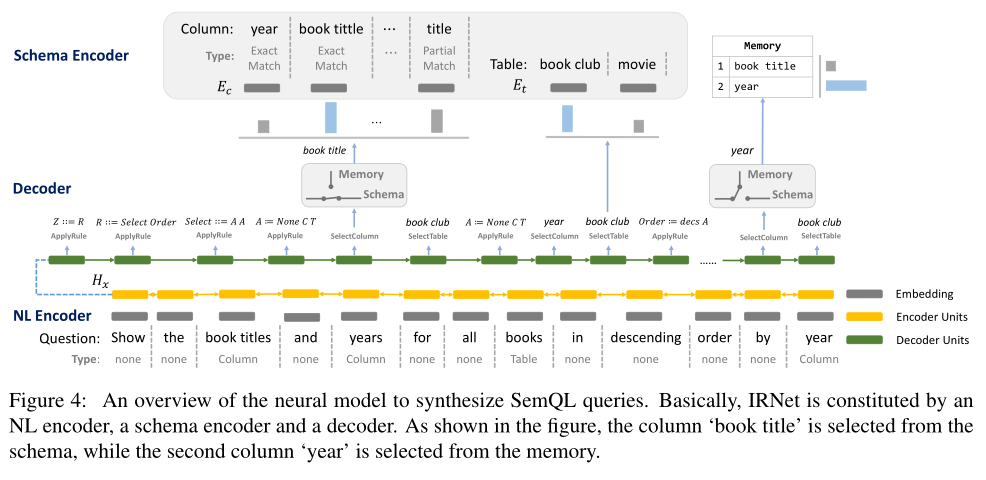
输入:
- 问题Natural Language(Figure4的最下面)
- 数据库模式A database schema (Figure4的最上面左边)
- 模式链接结果The schema linking results(Figure4的最上面右边)
为了解决the lexical problem,将schema linking的结果应用到NL和Schema中。设计了a memory augmented pointer network去 select columns,这个network决定是从memory中选择column还是从schema of database中选择。
NL Encoder:对Question进行编码。把Question按照Schema Linking分成不同的Spans;把每个Span中word的embedding及Span类型的embedding求平均后作为Span的embedding;在所有span的embedding之上,用一个Bi-LSTM进行编码后,将隐层作为输出。
Schema Encoder:对Database Schema进行编码。(a)把Schema中Column words的embedding取平均作为初始表示;(b)在span embedding的基础上用attention得到context vector;(c)把column type也转化为一个embedding vecotr。以上(a)、(b)、(c)相加得到schema encoder。
Decoder:生成SemQL。 此处IRNet定义了三种不同类型的操作——$APPLYRULE、SELECTCOLUMN、SELECTTABLE$。APPLYRULE选择特定的规则生成语法树,而SELECTCOLUMN和SELECTTABLE选择相应的column或table进行填充。
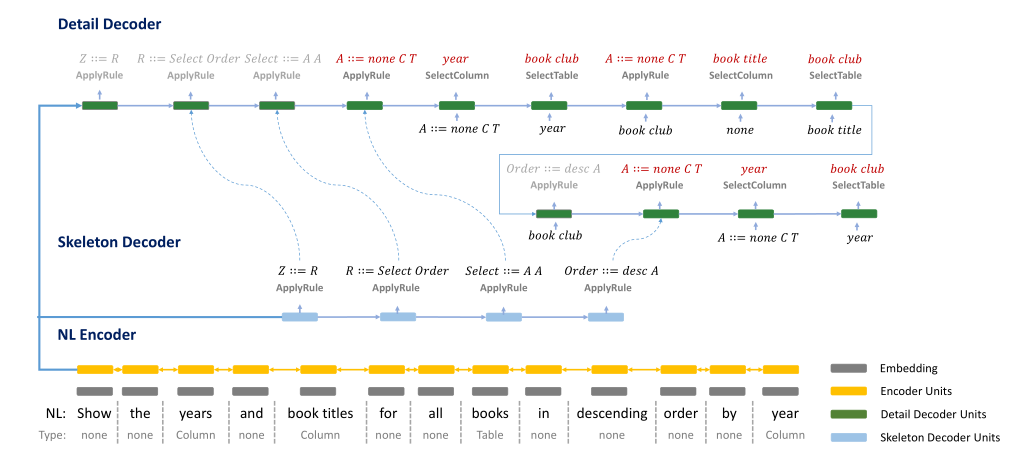
为了提升模型的准确率,IRNet使用了memory机制和coarse-to-fine的形式。(1)Memory:帮助细化column的选择机制。当一个column被选择后,将会把这个column从schema中移除,同时记录在memory中。下次当这个column再次出现,算法将决定是从scheam中进行选择,还是从memory中进行选择。(2)Coarse-to-fine:分两阶段由粗到细生成SemQL。第一阶段生成一个SemQL查询的skeleton,第二阶段通过选择column和table在skeleton中填入细节,执行过程如下图所示。
3. 实验
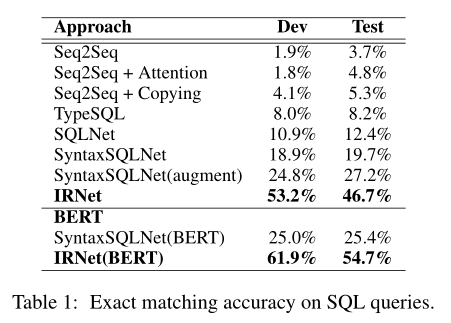
IRNet的表现明显优于所有的基线。在测试集上,它比SyntaxSQLNet获得了27.0%的绝对性能提升。与执行大规模数据扩充的SyntaxSQLNet(augment)相比,它也获得了19.5%的绝对改善。当加入BERT时,SyntaxSQLNet和IRNet的性能都得到了很大的提高,它们在开发集和测试集上的精度差距也加大了。
论文最后进行了错误案例分析。在Dev Set上IRNet共有483个错误预测。主要分为三类:Column Prediction(占比32.3%),Nested Query(23.9%),Operator(12.4%)。
- Column Prediction错误:基于字段值(cell value)没能正确找到对应的column。
- Nested Query错误:大部分是由于Extra Hard level的复杂嵌套查询没能准确构造。
- Operator错误:部分operators的选择要求机器有一定常识,如“from old to young”需要把年龄降序排列。
加入BERT后,Column Prediction和Operator两类错误有所改善。引入BERT进行输入编码的方法如下图所示。同样以Question、Database Schema、Schema Linking Results作为输入。对应每个span取words和type的平均值作为该span的encoding。对Schema,在column每个word上用一个Bi-LSTM输出隐层,加上column type的encoding作为column最后的encoding。
根据论文描述,一些可能的改进思路:
- 改善Column Prediction:现有column的识别基于string-match,如果改为embedding-match应该可以改善column的识别准确率;利用DB Content提升从cell value识别column的能力。
- 改善Nested Query:Extra Hard level的训练样本有限,可考虑通过数据增强来提升模型效果。
- 对SemQL的改善:继续加强SemQL来改善NL和SQL之间的mismatch部分,解决self join等表达问题。
参考文献
1. Towards Complex Text-to-SQL in Cross-Domain Database with Intermediate Representation (arxiv.org)