RAT-SQL阅读笔记
本篇论文研究的问题是:当把自然语言问题翻译成SQL查询,从数据库中搜集数据来回答问题时,现在语义解析模型很难泛化到未见过的数据库模式上。主要的泛化挑战有两个:1、语义parser对数据库关系进行可访问的编码,2、对数据库表列和它们在给定查询问题中的提及进行对齐建模。针对这两个挑战,作者提出了一个统一的框架,基于关系感知的self-attention机制,以解决模式编码、模式链接以及text2sql编码器中的特征表示。作者把这个框架应用到Spider数据集上,取得了57.2% exact match accuracy,在当时实现了SOTA。和BERT一起用,达到了65.6%。此外,最重要的是 模型在对模式链接和对齐的理解上有了质的提高。
论文地址:ACL2020 RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers
代码地址:rat-sql
1、现有的方案
现有的方案:由于text2sql是一个seq2seq的任务,utterance translation to sql query,所以研究的论文的点主要有:
- 针对encoder编码器的优化
- 生成sql解码器的优化
- 查询语言和sql之间的差异,使用formal language(形式化查询语言),来更好的对齐查询语言和sql语句
- Encoder embedding的预训练
- Decoder的预训练
本文的方案:这篇论文主要的工作是encoder部分优化。
2、提出问题
论文首先就Schema Encoding和Schema Linking进行了介绍。Schema Encoding顾名思义就是对表结构(表名、列名、列类型、主键、外键等等)进行编码,以便后续模型训练使用。Schema Linking则是要把Question中表述的内容与具体的表名和列名对齐。
由于spider数据集的train、test是没有重叠部分,所以是zero shot的预测,这种情况下,模型对schema的泛化能力就至关重要了。
这个泛化问题的挑战主要有三方面:
- 任何Text-to-SQL解析模型都必须将模式编码为适合于解码可能涉及给定列或表的SQL查询的表示形式。
- 这些表示应该编码schema模式的所有信息,比如它的column types列类型、外键关系和用于数据库连接的主键。
- 该模型必须能识别用于指代列和表的查询语言,这可能与训练中看到的参考语言有所不同,也就是模型得有 schema linking 能力(schema linking: 可以把问题中提到的实体引用与预期的模式列或表很好的对齐)
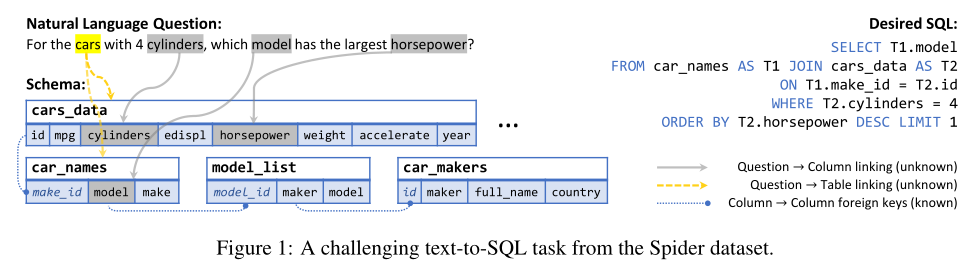
图1解释了在linking时存在ambiguity 的情况,问题中的“model”指的是 car_names.model 而不是 model_list.model;为了解决ambiguity 的情况,the semantic parser 需要同时考虑 schema relations 和语义信息。
之前的工作GNN encoder使用图神经网络,主要是用有向图来表示外键之间的关系,但是这种方法有两个缺点:
- 没有将schema与question结合起来编码,因此,在列和问题词被表示之后(这里的表示主要是embedding词向量和schema的一些内容),对schema linking模式链接的推理会变得很困难
- 将模式编码期间的信息传播限制在预定义的外键关系图中,这就没有考虑全局信息,之前的研究中已经证明全局信息对有效的表示结构关系非常重要。
这篇论文提出的RAT-SQL方案,是对数据库schema 和 问题question的关系结构有效编码;它使用 relation-aware self-attention (关系感知的self-attention Self-Attention with Relative Position Representations - ACL Anthology),把 schema entities 模式实体和问题词的全局推理,与对预定义模式关系的结构化推理 结合了起来。通过实验证明,RAT-SQL能够建立更准确的问题与模式列和表的真实对齐的内部表示。
3、Relation-Aware Self-Attention
Transformer结构是一系列self-attention layers的叠加。考虑 $x_i$为输入,self-attention layer的输出为 $y_i$。每一层的处理过程如下。其中FC为全连接层,LayerNorm是进行normalization。
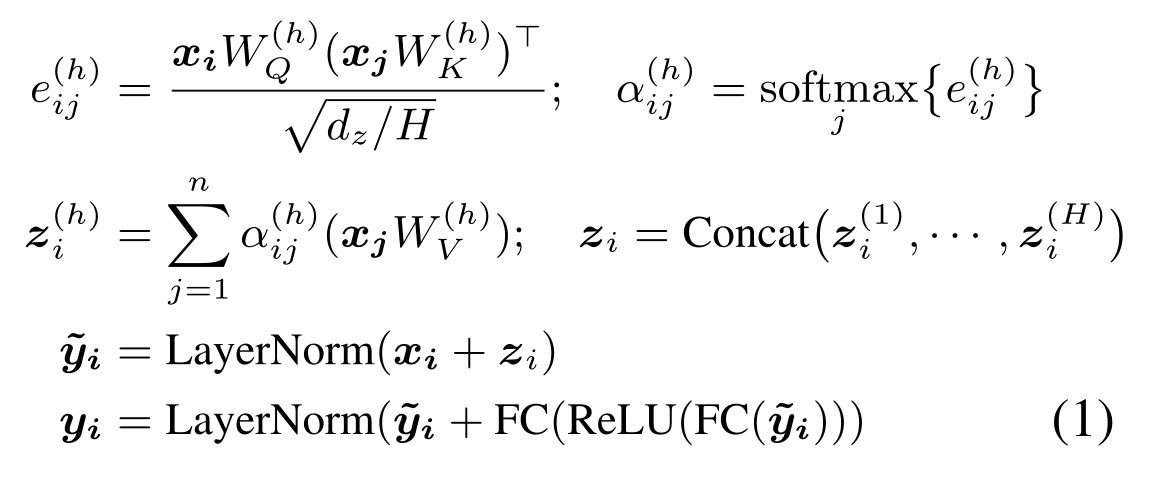
从Transformer架构理解,$e_{ij}$为$x_i$的query vector与$x_j$的key vector的点积得分;$\alpha_{ij}$为$x_i$对不同词向量的注意力权重;$z_i$为$x_i$的自注意力输出。普通Transformer结构擅长学习到不同$x_i$之间的关系,但如果$x_i$之间有预先定义好的关联关系,就无法表示出。
Shaw et al. (2018)提出了relation-aware self-attention的方法。即关系感知的自注意力,这是一个对半结构化输入序列embedding的模型,它联合编码了输入中预先存在的关系结构,以及同一嵌入中序列元素之间的诱导 “软 “关系。schema 的 embedding和 linking 自然而然作为一个feature。
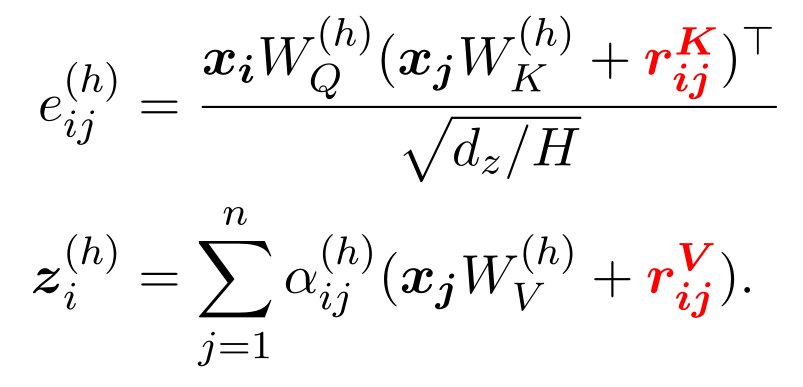
RAT-SQL基于此进行了进一步的引申,使得该Transformer结构可以表示任意的关系信息。$r_{ij}$表示两个输入元素$x_i$和$x_j$的已知关系编码,定义$r_{ij}^K=r_{ij}^V=Concat(\rho_{ij}^{(1)},…,\rho_{ij}^{(R)})$。其中假设有R个关系对,而$\rho_{ij}^{(s)}$为通过学习得到的对关系$R^{(s)}$的向量表示。部分关系如下表:
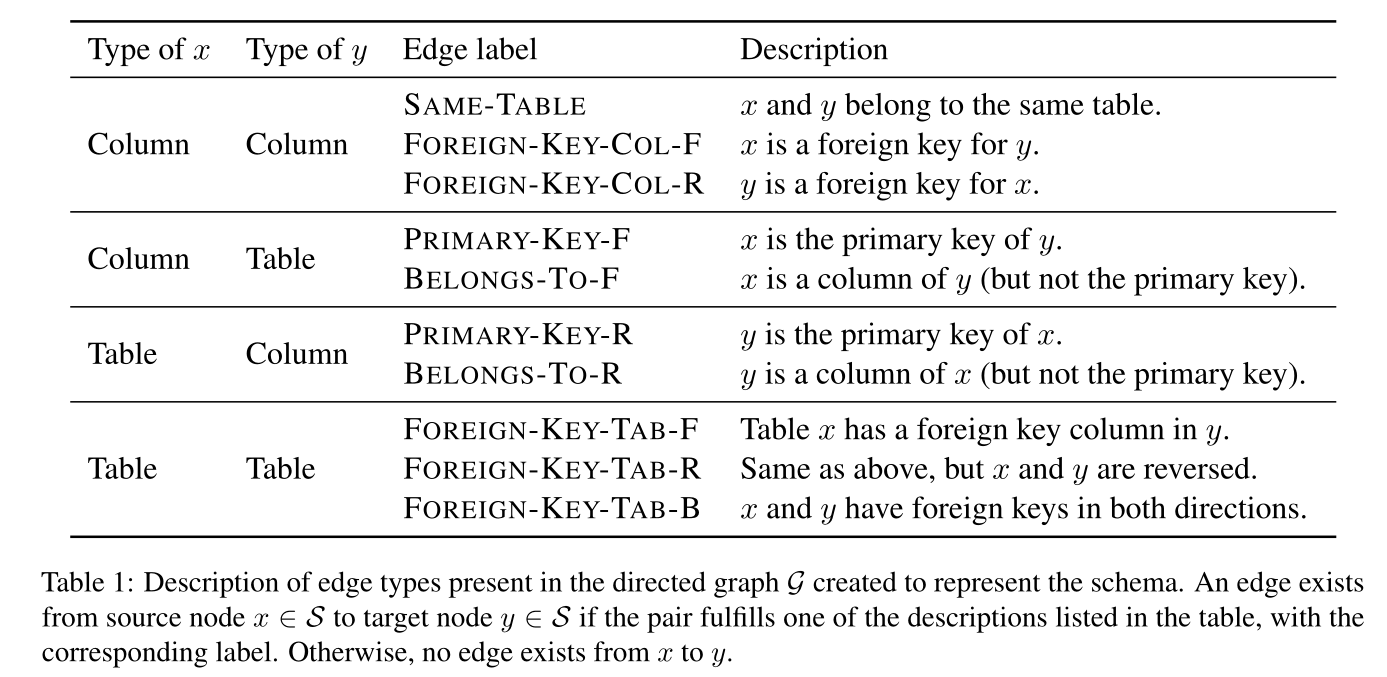
4、RAT-SQL
模型结构示意图如下,分为encoding和decoding两个阶段,下面分步解释。
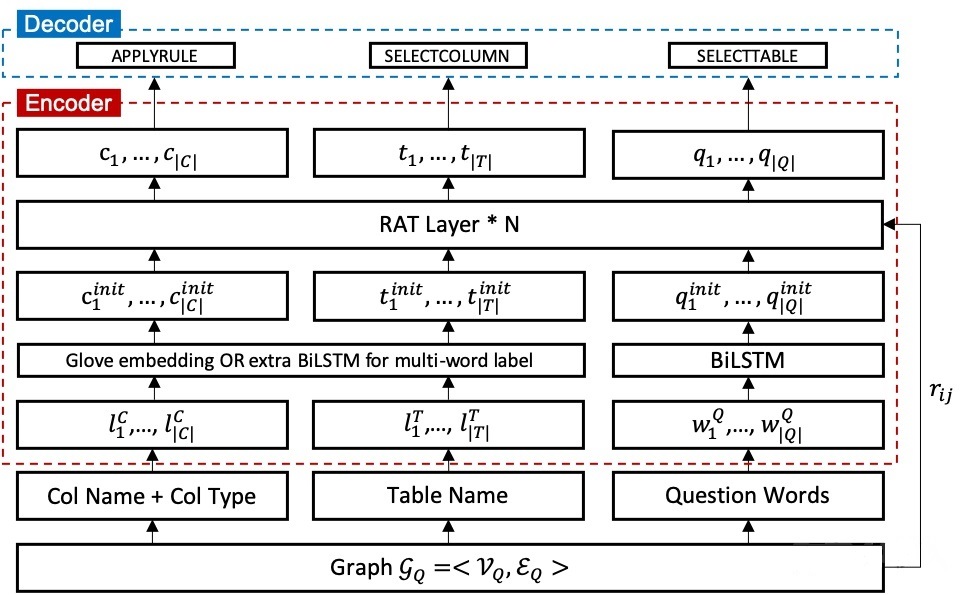
4.1 构造Graph $G_Q$
图顶点集合 $V_Q$ 由三部分组成:column names,table names以及question words。对于column,同时在顶点label中加入column type。
这里需要注意的是,有的列是主键,有的是外键,列的type有NUMBER和TEXT。
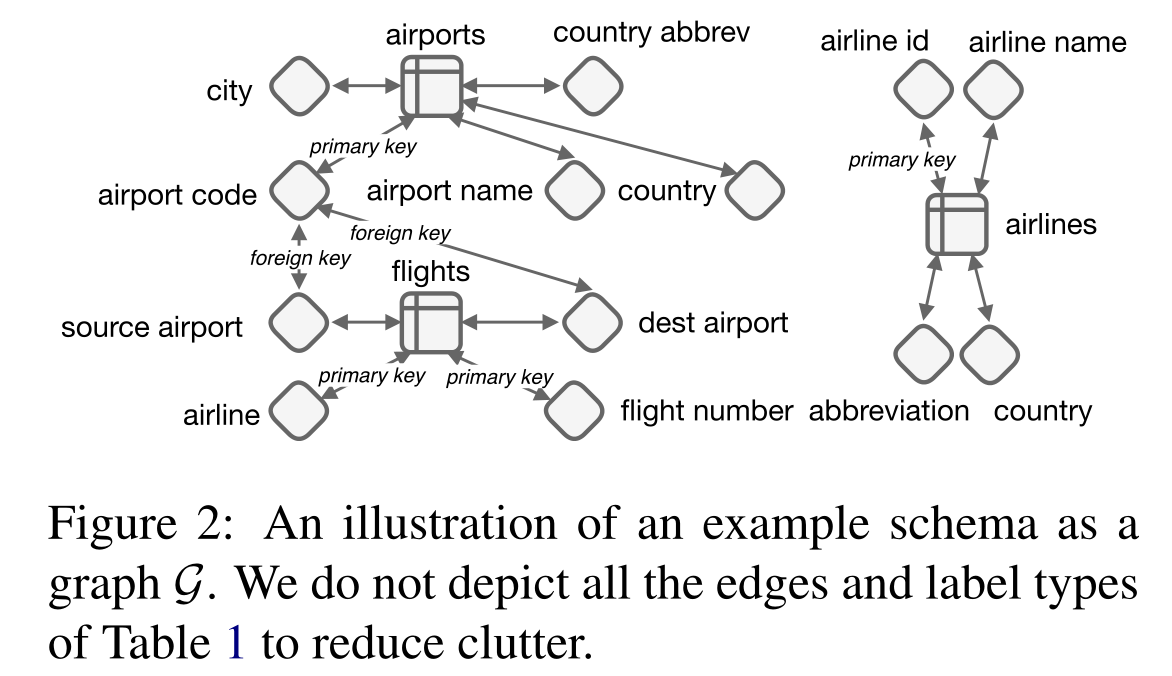
本文使用有向图来表示数据库schema,node节点包括表和列,表的label是表名单词,列字段的label会在列单词前加type,边是数据库已经定义的关系。
这里需要注意的:图对已有信息都覆盖了,但是对那些没见过的schema就不能精确编码了。所以,本文希望通过联合学习question和schema来让模型掌握这种能力,能够对已有信息未见过的schema精确编码。因此,作者定义了一个新的图:question-contextualized schema graph :node包括question words, 边是已知schema 边 + question words 和 schema 的 特殊关系(完全匹配、部分匹配)
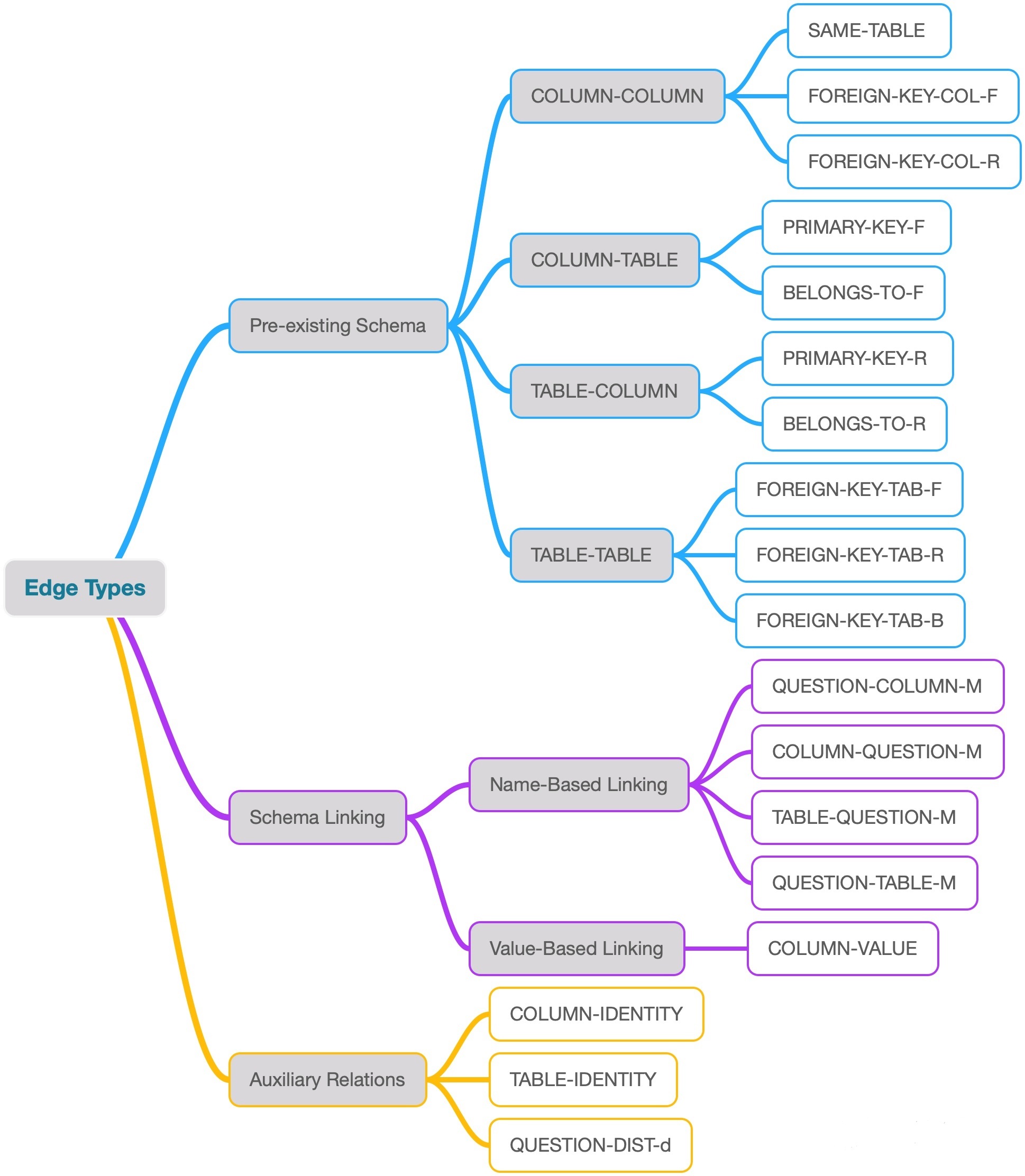
图的边集合$E_Q$由三部分组成:首先是Database Schema所定义的表连接关系,table和column的包含关系等等;其次是通过schema linking得到的question和schema之间的对应关系;最后是为辅助relation-aware self-attention而定义的Auxiliary Relations。各种edges的类型整理如下图,具体定义请参考论文。
4.2 Relation-Aware Input Encoding
针对每个表、列节点,作者这里使用了glove的embedding来获得词向量,并用BiLSTM来处理词向量,并用另外独立的BiLSTM来获取question的embedding
输入X是所有节点表示的集合:
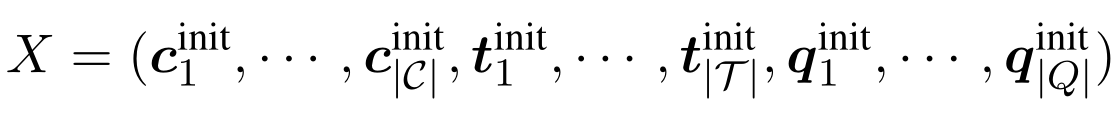
这里的encoder会堆叠多层的Relation-aware self-attention层,最后将第N层的输出作为编码器的最终输出。
同时,论文也使用预训练模型BERT来获取初始节点Embedding。同时也添加了许多附加关系,使得节点之间两两互有关系,构成一个完全图。
4.3 Schema Linking
由于我们的输入是一张张图,图的边包括已存在主外键关系,这里我们需要构建问题中提到的词与数据库中已存在的表、列(字段)的边。这里的关系有两种:1、匹配的名称( matching names );2、匹配的列的值(matching values)
Name-based linking:包含完全匹配和部分匹配;完全匹配就是字符串和数据库的表列名完全相同,部分匹配是字符串只是表列名的子集。这里使用N-Gram进行匹配,当然效果是很差的。
Value-based Linking:主要是确定question中的某个词是否是数据库表中某列的一个值。这对于模型的表现提升很大。这块其实比较难,因为列的值千变万化,且有的需要背景知识。(这块作者是说,将这块外包给数据库引擎来做,不需要将模型暴露给数据,通过数据库索引和文本搜索快速检索单词匹配,这里具体是如何?作者并没有解释清楚。)
4.4 Memory-Schema Alignment Matrix
一般出现在SQL句子中的表和列,一般在question中会提到相关的词语;为了验证,使用relation-aware 的attention来作为一个指针机制。使用Encoder最后一层的输出来计算一个alignment矩阵,用于可视化schema linking的对齐效果。
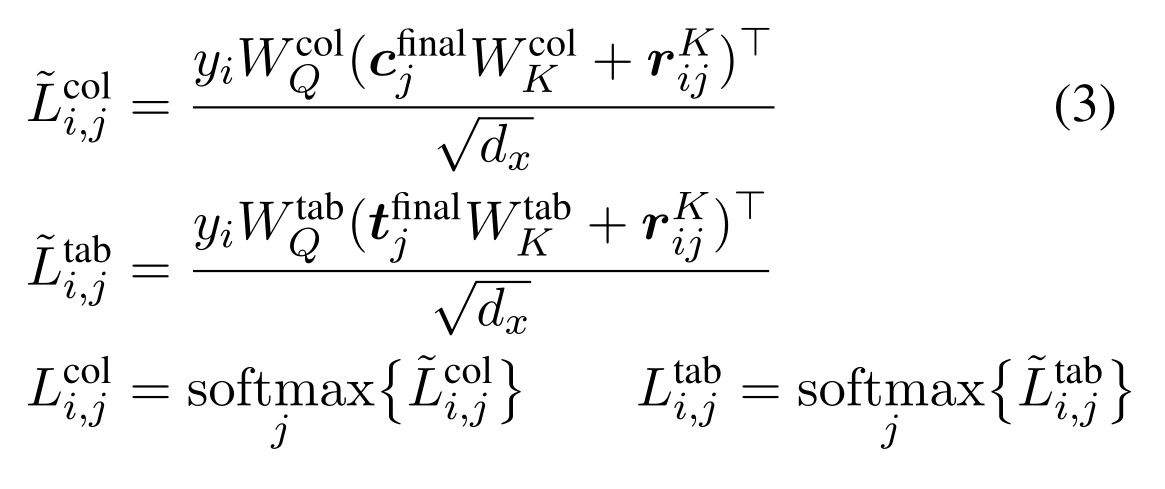
公式中的对齐矩阵应该类似于真实的离散对齐,所以需要尊重某些约束条件,如稀疏性,不过随着编码器被充分参数化后,稀疏性往往随着学习而产生,我们也可以使用一个明确的目标来鼓励它。
(作者在附录中证明了,这个方式只在这个对齐方式,在早期的实验中可以帮助模型,后期对模型的performance没有帮助;或者在transformer层较少的时候有用)
4.5 Decoder
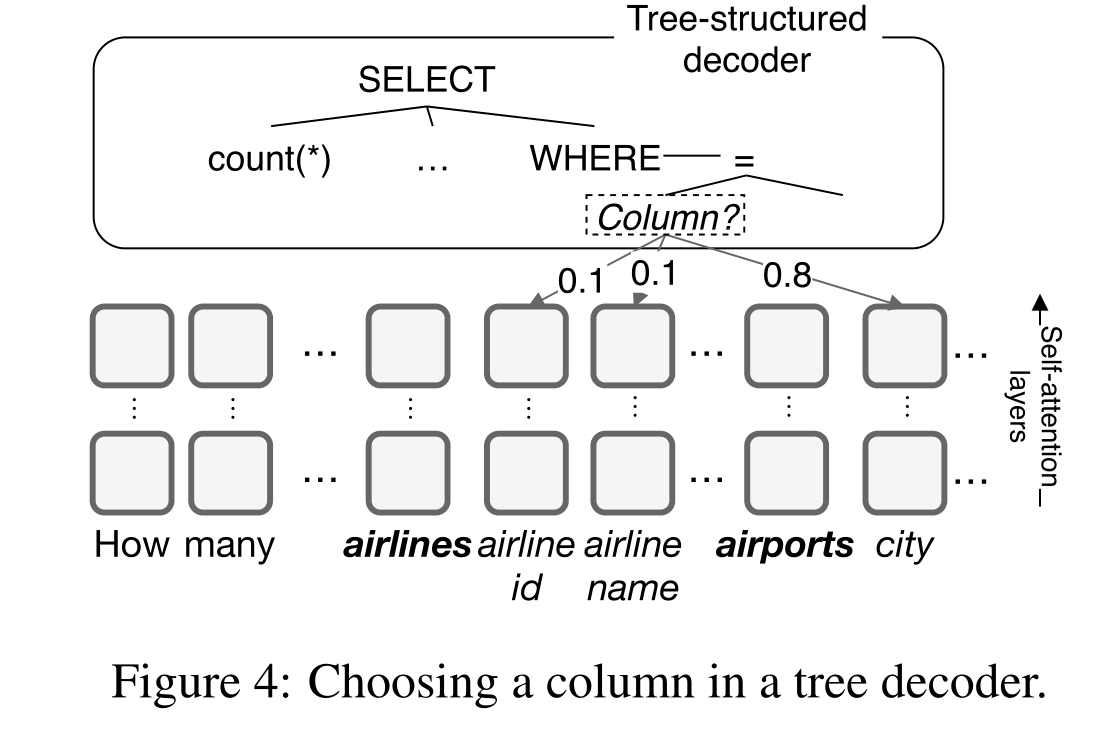
在encoder输出的向量之上通过使用LSTM输出一系列解码器动作来生成作为深度优先遍历顺序的抽象语法树AST(Abstract Syntax Tree):
- 将最后生成的节点扩展成一条语法规则,用APPLY RULE来生成基本结构;
- 当完成一个叶子结点时,从schema中选择一个column或table。用SELECT TABLE或者SELECT COLUMN来完成table name或column name的选择填充。
- AST生成后,可进一步推断出最终的SQL query。
详情参考论文: Pengcheng Yin and Graham Neubig. 2017. A Syntactic Neural Model for General-Purpose Code Generation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 440–450.
5 实验
作者对输入的文本做了lemmatized ,这个在做n-gram匹配时可以用得上;作者这里尝试了 4、6、8层的Rat-layers,本实验主要基于Spider、WikiSQl这两个数据集。
5.1 在Spider数据集上的结果
在Spider数据集上实验结果如下:
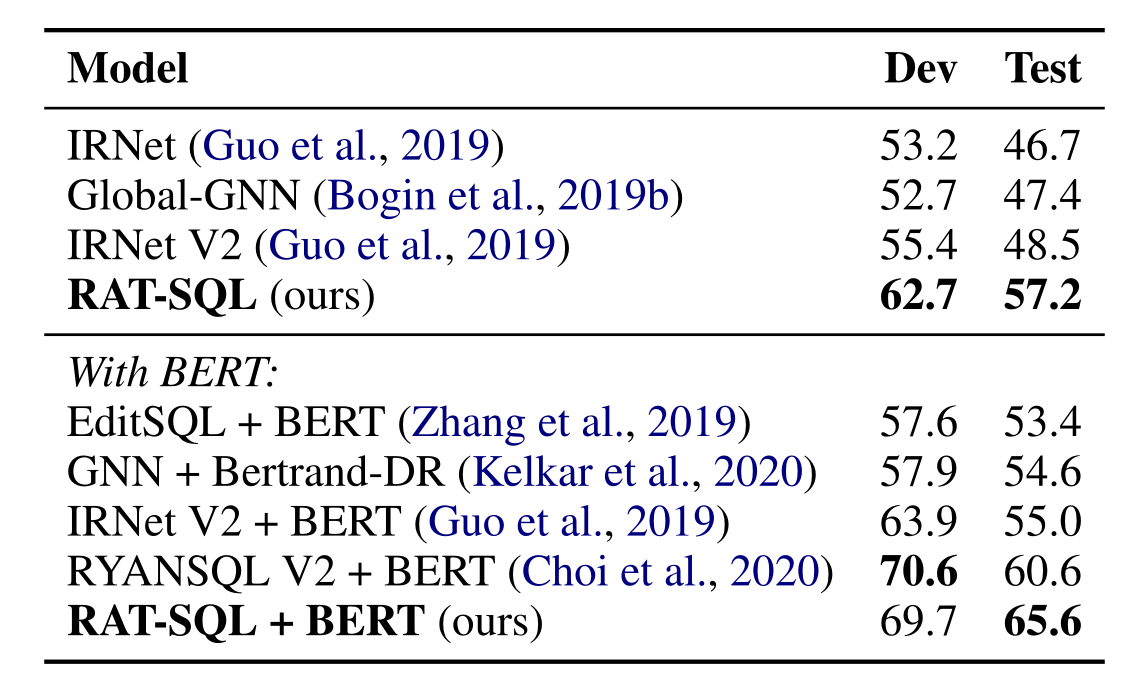
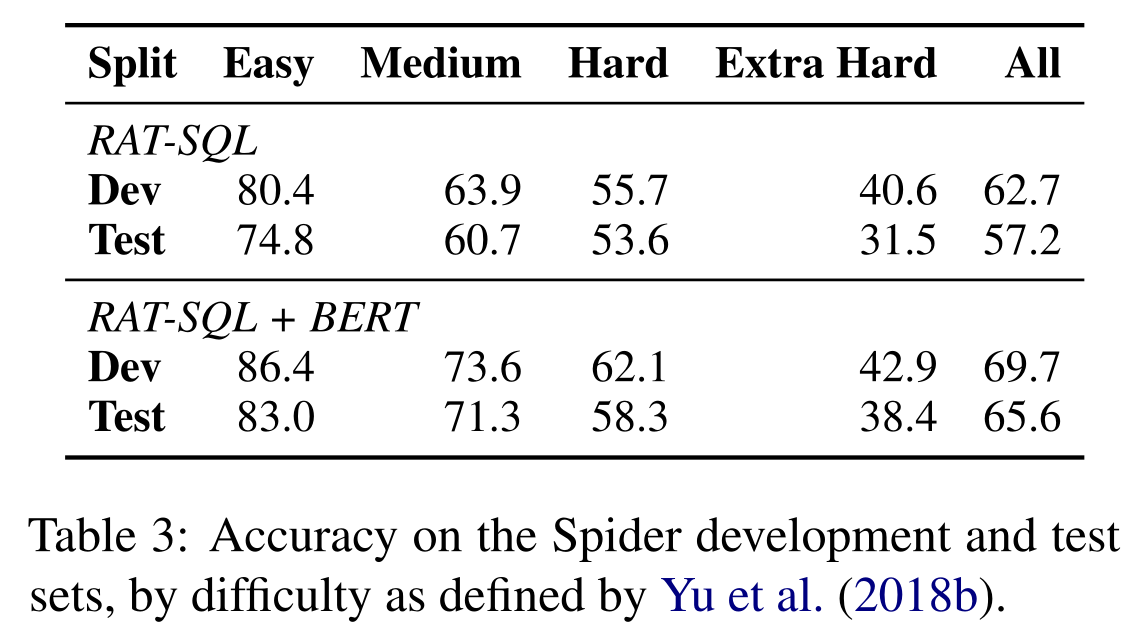
在各个难度子集上的结果如下:
同时,文章进行了消融实验Ablation Study,结果如下:
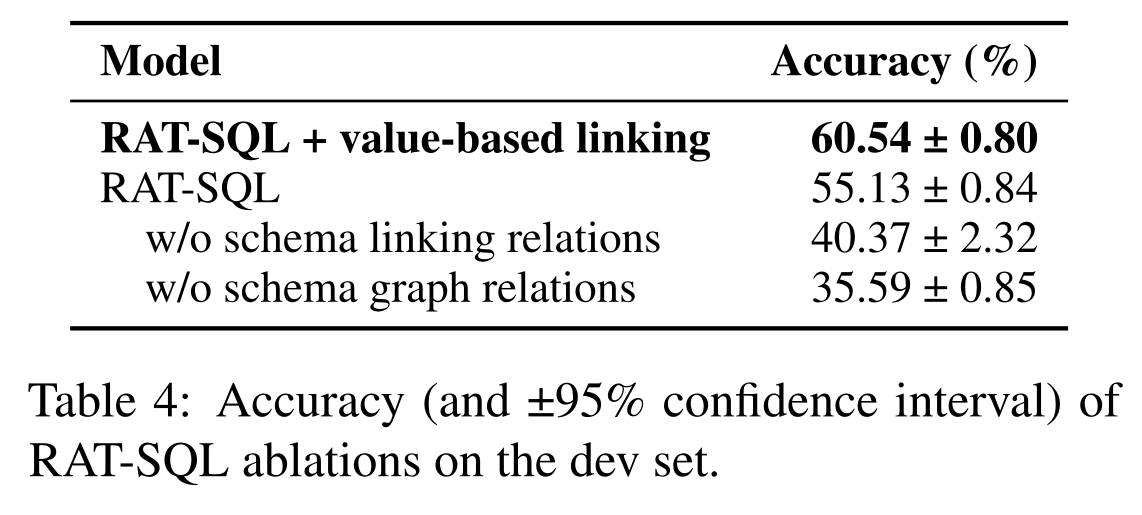
结果显示使用了 schema-linking、graph-relation、value-linking会进一步提高表现。
5.2 在WikiSQL数据集上的结果
作者也尝试在WikiSQL数据集上进行了评估。实验结果如下:
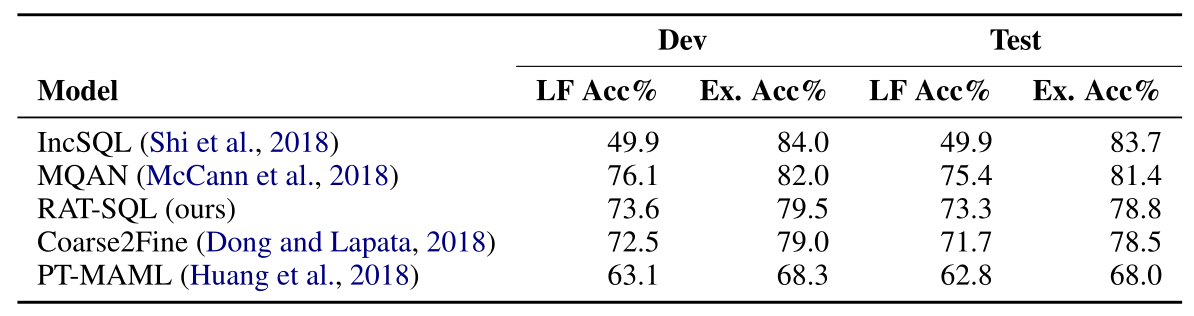
可以看到,模型相比于WIkiSQL上一些单纯的”slot filling”的方法也取得了具有竞争性的表现。
6 讨论
6.1 Alignment的作用
将question中对应的columns和tables识别出来,不仅仅是提升了SQL中对应columns/tables的准确率。这种对齐(alignment)还为question中其他部分的识别提供了一个良好的基准。如下图中,不只是question中“horsepower”被识别出与“column:horsepower”对应,同时整个word span “the largest horsepower”也被对齐到“column:horsepower”。
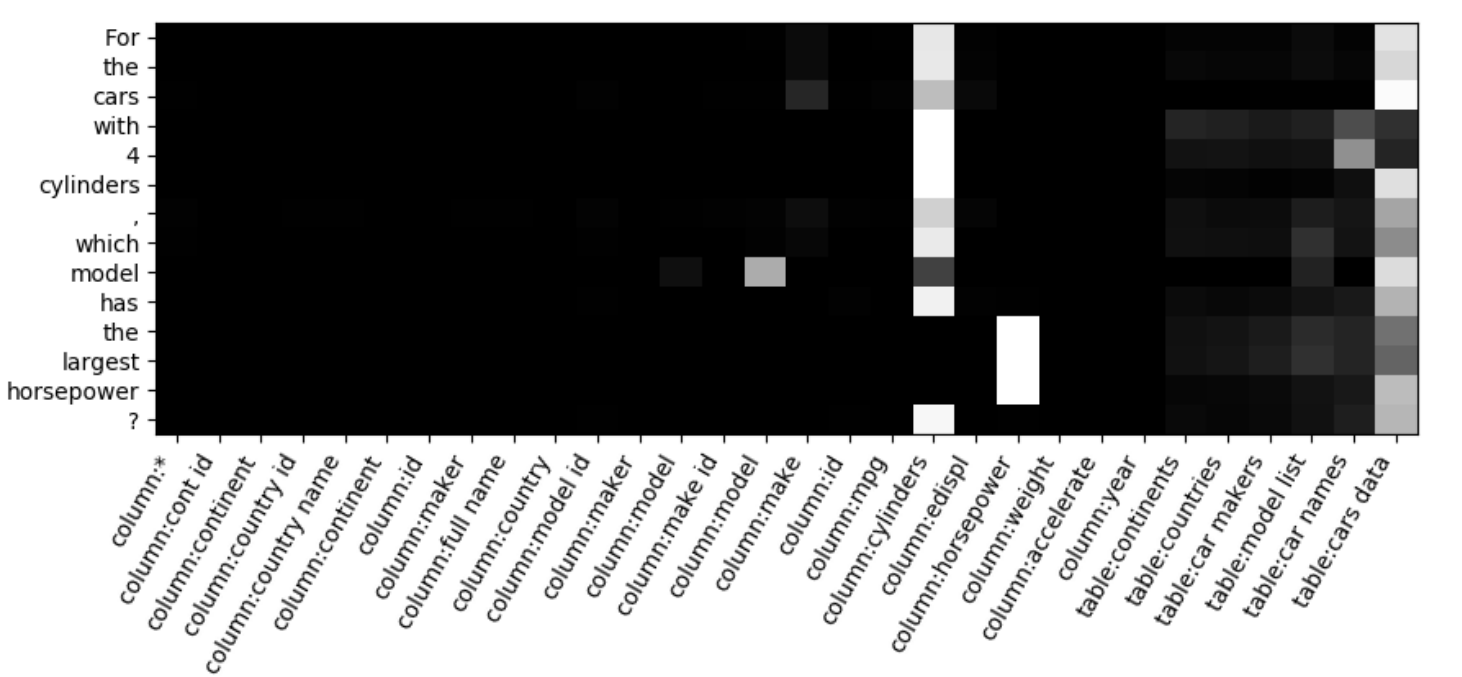
图中展示了模型对图1示例生成的对齐。可以看到查询问题和 表列的对齐效果;对于引用列的三个单词((“cylinders”, “model”, “horsepower”),对齐矩阵正确地标识了它们对应的列,其他的词受到了这三个词很大的影响,导致稀疏的span-to-column对齐,例如“largest horsepower” 到 horsepower.。表cars_data和cars_names是由单词cars隐式提到的,所有被模型识别出来了,但cars_maker 却没有,说明模型在对齐上做的还算可以。
6.2 使用Schema Linking的必要性
为了探讨模型选择了错误的表列的频率,作者做了一个oracle experiment(让模型中特定模块永远产出正确的结果然后再评估模型准确率):在每一个语法非最终的终端,解码器被强迫选择正确的产生方式使得和ground truth完全匹配,后续的解码流程基于这个选择进行。结果如下图

这里的Oracle columns指的是总是给模型提供正确的table/column,Oracle sketch指的是给出正确的AST结构。可以看到,如果都可以正确给出,模型可以达到99.4的准确率,证明了模型中的语法基本可以覆盖所有的Spider中的例子。
6.3 误差分析
主要有三种误差:
- 18%的错误预测是因为SQL语法表达不同,而执行结果是正确的。(例如ORDER BY C LIMIT 1 vs.SELECT MIN(C))
- 39%的错误预测是因为SELECT 子句中的错误/缺失/多余的column。这是schema linking的一个限制,部分错误较难解决,因为一些questions中并未明确所需column。
- 29%的错误是因为WHERE语句不完整。一个常见的例子是特定领域的措辞,例如“older than 21”,这需要背景知识将其映射到 age > 21 而不是 age < 21。此类错误在域内微调后消失。
创新点
RATSQL是ACL 2020上的一篇用于解决Spider数据集上Text-to-SQL问题的论文,后续的LGESQL也是在篇论文的基础上改进的。文章的主要创新点在于:
- 在Encoder中加入relation-awareself-attention组成RAT层代替transformer层对输入进行encode,relation一共有33种,每两个单词之间都会有一个relation。利用schema linking同时把显式关系(schema)和隐式关系(question和schema之间的linking)都考虑在encoding中,完善了模型的表示能力。假设一共有R种不同的关系,rij可以定义为R个特征向量的拼接,对于每一种关系,如果xi和xj有这一关系,就将对应的特征向量作为参数进行学习,否则就置为零向量。
- 构造Graph,图顶点集合Vq由三部分组成:column names,table names以及question words。对于column,同时在顶点label中加入column type。边集合Eq 由三部分组成:首先是Database Schema所定义的表连接关系,table和column的包含关系等等;其次是通过schema linking得到的question和schema之间的对应关系;最后是为辅助relation-aware self-attention而定义的Auxiliary Relations。
- 在encoder输出的向量之上通过一系列的预测动作来构造AST(Abstract Syntax Tree):首先,用APPLYRULE来生成基本结构;然后,用SELECTTABLE或者SELECTCOLUMN来完成table name或column name的选择填充。AST生成后,可进一步推断出最终的SQL query。
- 在encoder最后一层计算一个对齐矩阵,用于可视化查看模型在question word和schema word之间的对齐效果。