
LGESQL阅读笔记
论文地址:ACL2021 LGESQL: Line Graph Enhanced Text-to-SQL Model with Mixed Local and Non-Local Relations
代码地址:LGESQL
摘要
这项工作旨在解决 Text-to-SQL 任务中具有挑战性的异构图(由不同成分组成的图)编码问题。以前的方法通常是以节点为中心,仅仅利用不同的权重矩阵来对边类型进行参数化,这些方法
- 忽略了嵌入在边的拓扑结构中的丰富语义信息
- 无法区分每个节点的局部和非局部关系
为此,我们提出了一个 Line Graph Enhanced Text-SQL(LGESQL) 模型来挖掘底层的关系特征,而无需构建元路径。由于line graph的存在,信息不仅通过节点之间的连接,而且通过有向边的拓扑结构更有效地传播。此外,在图的迭代过程中,局部和非局部的关系都被不同程度地整合。我们还设计了一个辅助任务,叫做图修剪(graph pruning),以提高Encoder的辨别能力。在撰写本报告时,我们的框架在跨领域文本到SQL基准的Spider上取得了 state-of-the-art(GLOVE为62.8%,ELECTRA为72.0%)。
1. Introduction
Text-to-SQL任务旨在给出相应的数据库模式,将自然语言问题转换为SQL查询。它已经在学术界和工业界被广泛研究,以建立数据库的自然语言接口。
一个艰巨的问题是如何联合编码问题和数据库模式(包括表和列),以及这些异质输入之间的各种关系。通常情况下,以前的文献利用以节点为中心的图形神经网络(GNN)来汇总相邻节点的信息,GNNSQL采用了关系图卷积网络(RGCN)来考虑模式项之间的不同边类型。
然而,这些边特征是直接从一个固定大小的参数矩阵中获取的,可能会有一个缺点:不了解上下文信息,特别是边的结构拓扑。元路径(Meta-path ) 被定义为连接两个对象的组合关系,它可以用来捕捉多跳语义,举例:在图1(a)中,Q-exact match-C 和 C-belong to-T 可以形成一个2跳元路径,表示某个表T 有一个列C正好在问题Q中被提到。
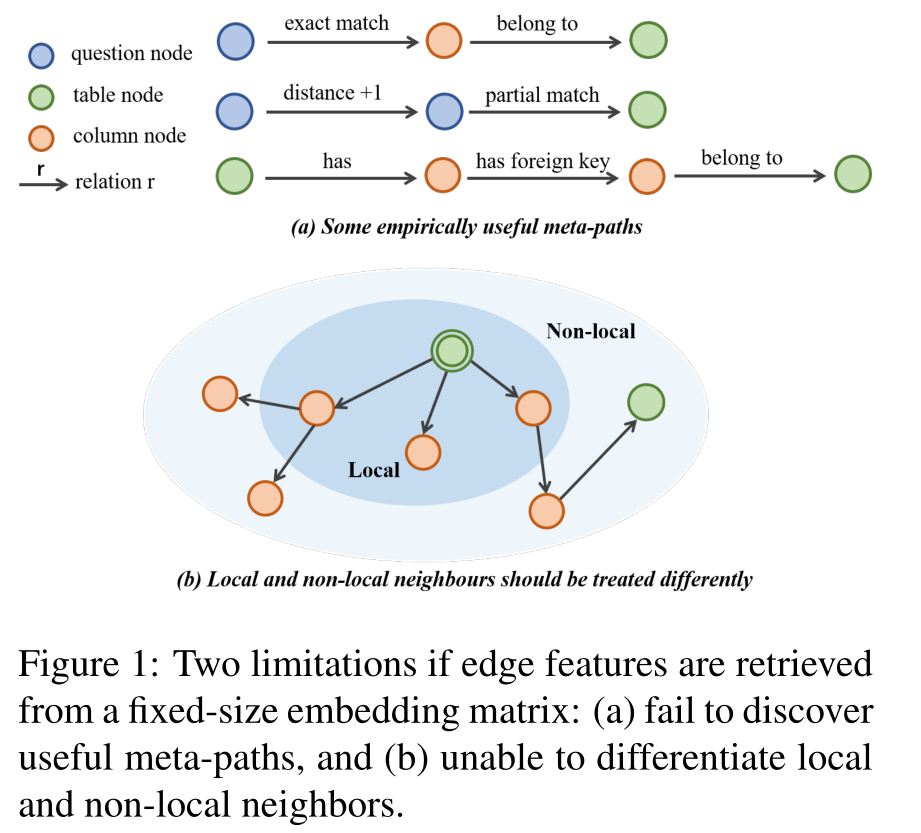
尽管RATSQL引入了一些有用的元路径,如 C-same table-C,但它处理所有的关系,无论是1跳还是多跳,都是以同样的方式(相对位置嵌入)表示在一个完整的图中。如果不区分局部(1跳邻居)和非局部邻居,见 图1(b),每个节点将平等地关注所有其他节点,这可能导致过度平滑问题 (局部和非局部邻居应该被区别对待)。
此外,元路径目前是由领域专家构建的,或者通过广度优先搜索进行探索。不幸的是,可能的元路径的数量随着路径长度的增加而呈指数级增长,在其中选择最重要的子集是一个NP-complete问题。
为了解决上述限制,我们提出了一个 Line Graph Enhanced Text-SQL(LGESQL) 模型,它明确考虑了边的拓扑结构。根据 line graph(线型图) 的定义,我们首先从原来的以节点为中心的图中构建一个以边为中心的图,这两个图分别捕获节点和边的结构拓扑。
两个图中的每个节点都从其邻域收集信息,并从双图中提取边缘特征来更新其表示。对于以节点为中心的图,我们将局部和非局部的边特征都纳入计算。局部边特征表示 1跳 关系,由 line graph 中的 node embeddings 动态 提供,而非局部边特征则直接从参数矩阵中提取,这种区别鼓励模型要更多地关注局部的边特征。
2. Preliminaries
2.1 Problem definition
整个输入节点为中心的异构图$G^n=(V^n,R^n)$由三种类型的节点组成,即$V^n=Q\cup T\cup U $
- 其中,Q为问题,T为对应的数据库 schema 的Table,C 为 column,R 是边的类型
- $|V^n|$是节点总数,$|V^n|=|Q|+|T|+|C|$
2.2 Meta-path
如图所示,一个 meta-path 代表一个路径
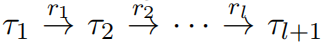
它在两个类型$\tau_1$和$\tau_2$ 的节点之间描述了一组复合关系 $r=r_1\circ r_2\cdots \circ r_l$ (即描述了两个节点之间存在的边的类型信息,边的类型包括 QUESTION,TABLE,COLUMN)。
在本文的讨论中,我们使用 local 来表示长度为 1 的路径(局部路径),而长度 大于1 的路径为非局部路径。关系邻接矩阵$R^{n}$中包含局部关系和非局部关系。
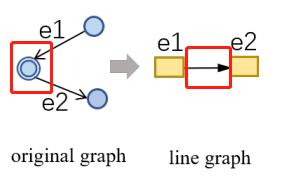
2.3 Line Graph
离散数学里面的对偶图,把原图的边转换为节点,把节点转化为边,以边为中心的异构图。
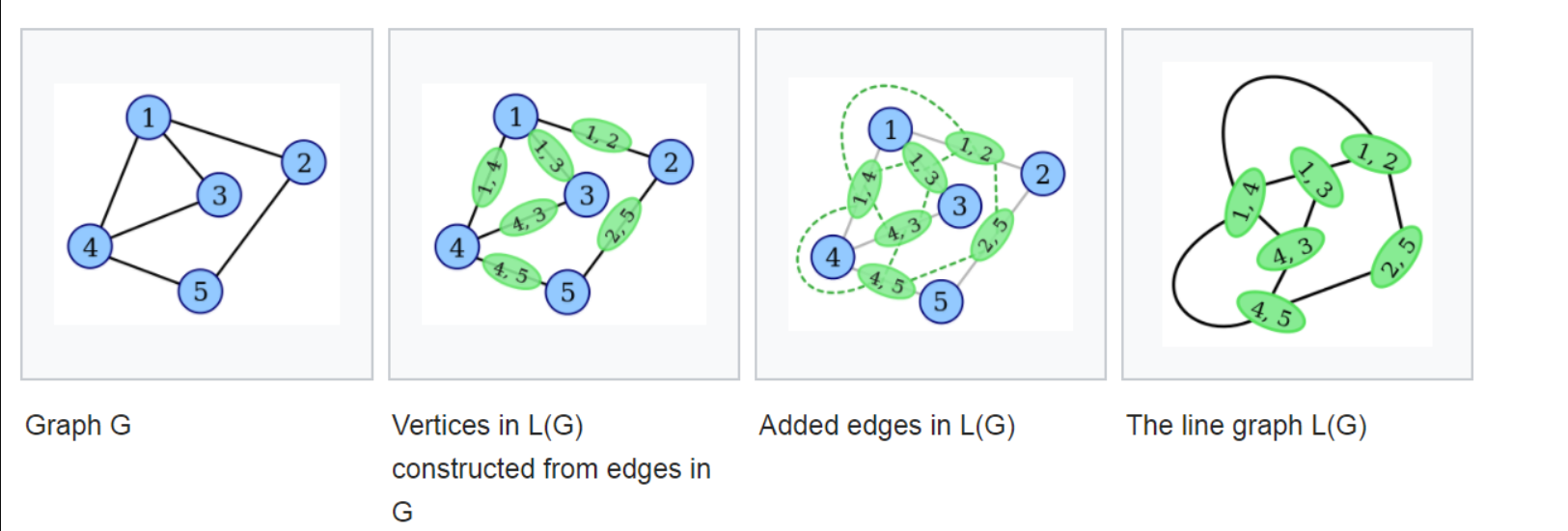
如图所示,原始图中有1-5共5个节点和 ${(1, 2), (1, 3), \cdots\}$ 等多条边。现在我们构造Line Graph。首先将图中所有的边全部变成Line Graph中的一个节点,然后如果两条边同时接到了一个点上,比如 ( 1 , 2 ) 和 ( 1 , 3 ) 那么这两条边对应到Line Graph中的节点就连一条边。
在 line graph$G^e=(V^e,R^e)$中的每一个节点$v_i^e,i=1,2,\dots,|V^e|$可以唯一映射到原始节点中心图$G^n=(V^n,R^n)$的一条有向边$r^n_{st}$,或者$v_{s}^{n}\to v_{t}^{n}$
Function f 将源节点和目标节点的索引元组(s,t)映射到 line graph$G^e$中点的索引(相当于把$G^n$中两个节点之间的边映射到$G^{e}$中的节点),表示为 i = f(s,t),反向映射表示为$f^{-1}$(相当于把$G^{e}$中的节点映射到$G^{n}$中的边)
在 line graph $G^{e}$中,如果$r^{n}_{f^{-1}(i)}$的 target node(目标节点)$v_{i}^{e}$的和 $r^{n}_{f^{-1}(j)}$的 source node(起始节点)$v_{j}^{e}$在原图$G^{n}$中都表示相同的节点,那么在线图$G^{e}$ 中,$v_{i}^{e}$和$v_{j}^{e}$之间就会存在一条有向边$r^{e}_{ij}$。
$r^e_{ij}$中包含了 meta-path $r^{n}_{f^{-1}(i)} \circ r^{n}_{f^{-1}(j)}$的信息(包含了原图中两个节点的信息 )
我们防止回溯的情况,其中两个反向边不会在$G^e$中连接,如图所示
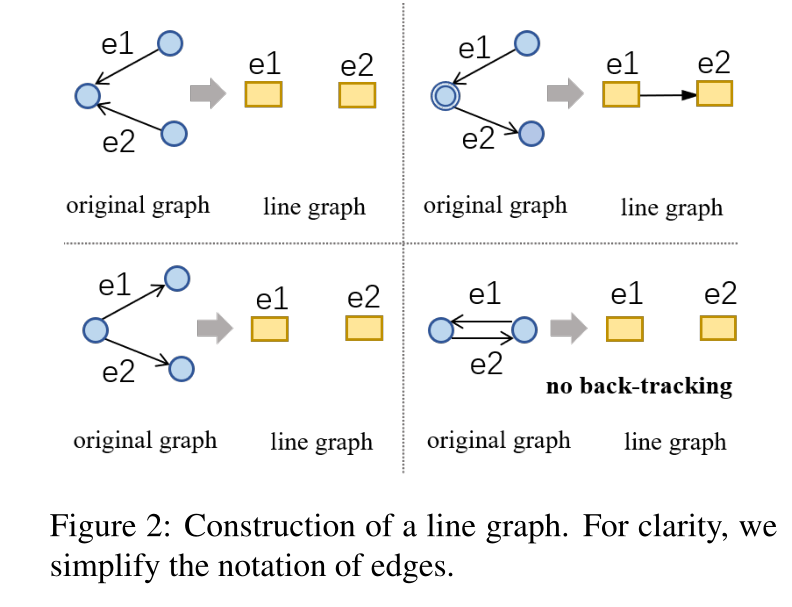
只使用$R^{n}$的局部关系作为 line graph $G^{e}$的节点集,避免在 line graph 中创建太多节点。对称的是,在line graph中$R^{e}$中的每条边,可以被唯一映射到原图中的节点集 $V^{n}$中,如下图
3. Method
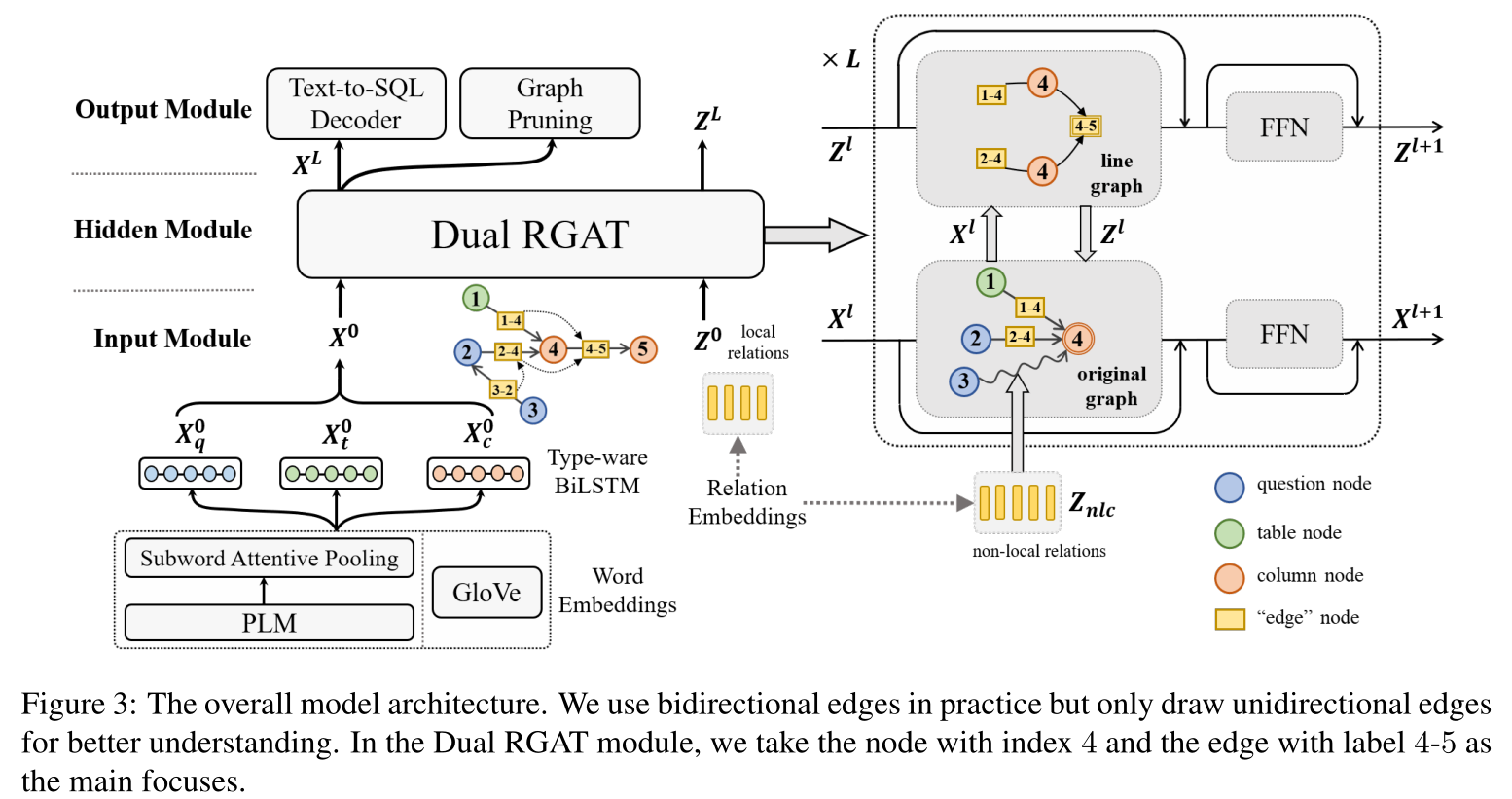
在构建了线图之后,我们利用经典的 encoder-decoer 结构为骨干作为我们的模型,LGESQL由三部分组成:
- graph input model(图形输入模块)
- line graph enhanced hidden module(线图增强隐藏层模块)
- graph output module(图形输出模块)
前两个模块旨在将输入的异构图$G^{n}$映射成 node embeddings X,X 的维度是$|V^{n}| * d$,其中d是图的 hidden size。
图输出模块检索并将 X 转化为目标SQL查询y。
3.1 Graph Input Module
这一部分的模型是为了获取节点和边的初始表示
- 对于边,初始的局部的边特征$\mathbb{Z}^{0}\in \mathbb{R}^{|V^{e}|\times d}$以及非局部特征$\mathbb{Z}_{nlc}\in \mathbb{R}^{(|R^{n}|-|V^{e}|)\times d} $都是直接从参数矩阵获得的。
- 对于节点,我们可以从GLOVE或者预训练的模型(PLM)如BERT中获取。
3.1.1 Glove
对于每个在question、table或column中的名称,使用Glove词向量时可以不考虑上下文直接在词典中拿到它们的embedding。然后将它们(这里的它们是指一个名称中包含的若干个word)按照所属部分(即是属于question,还是table,还是column)类型分别送入对应的BiLSTM中,并concatenate两端的hidden state。将得到的节点表示进行stack组成初始节点embedding矩阵$X^0\in \mathbb{R}^{|V^n|\times d}$。
3.1.2 PLM
使用预训练模型时,我们首先将所有的question和schema中的名字组成一个序列
其中类型信息$t_{i0}$和$c_{j0}$被插入到schema item之前。由于每个word都被分词成subword-level,所以要获取每个word的表示向量需要再加入一个subword attentive pooling layer来获取word的表示。
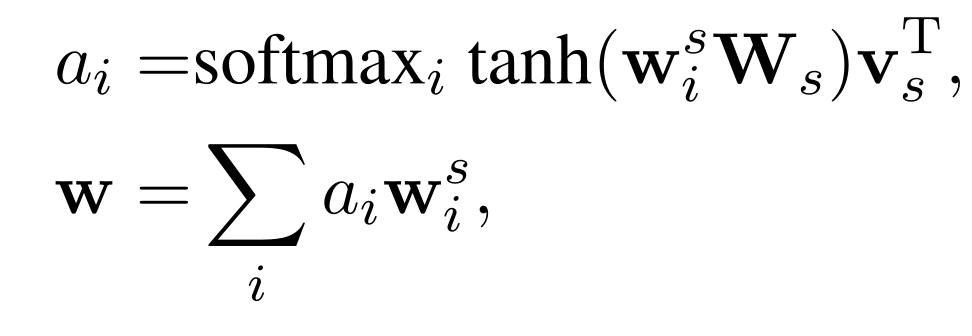
其计算过程与attention的计算差别不大。获得每个word的词表示后,也分别将它们按照所属部分类型分别送入对应的BiLSTM中,并concatenate两端的hidden state。将得到的节点表示进行stack组成初始节点embedding矩阵$X^0\in \mathbb{R}^{|V^n|\times d}$。
3.2 Line Graph Enhanced Hidden Module
包含 L 个堆叠的 dual relational graph attention network (Dual RGAT) 层
- 在每个层 $l$ 中含有两个 RGAT模块分别捕获 original graph 和 line graph 的结构信息。
- 每个图中的节点embedding都表示了对偶图中的边的特征信息。在这两个图中,一个图的 node embeddings 在另外的一个图中充当 edge features (边的特征)。例如, original graph $G^{n}$中的边的特征是由 line graph $G^{e}$中的 node embeddings 提供的。下图中节点图$G^{n}$使用的边特征 z (边1-4和2-4)来源于线图中对应的“节点”特征。
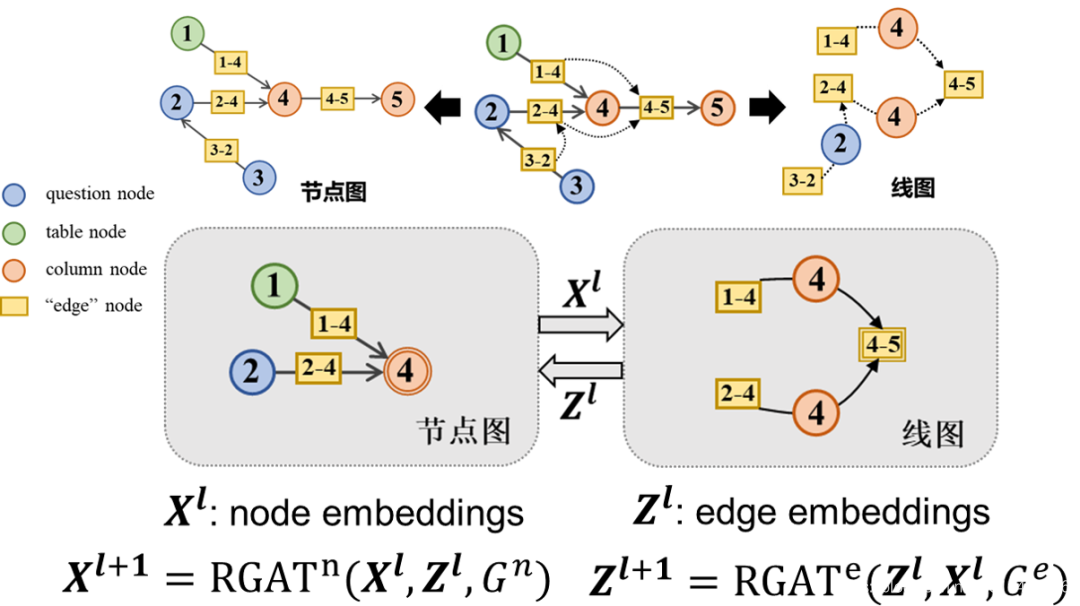
- 我们使用$\mathbb{X}^{l}\in \mathbb{R}^{|V^{n}|\times d}$来代表original graph $G^{n}$ 在第 $l$ 层的RGAT的 node embedding 输入矩阵,对于 $v_{i}^{n}$ 节点,我们的 embedding 用 $x_{i}^{l}$ 表示。
- 相同地,使用 $\mathbb{Z}^{l}\in \mathbb{R}^{|V^{e}|\times d}$ 以及 $z_{i}^{l}$ 来代表 line graph $G^{e}$ 的节点(这里指局部关系,即一跳邻居)
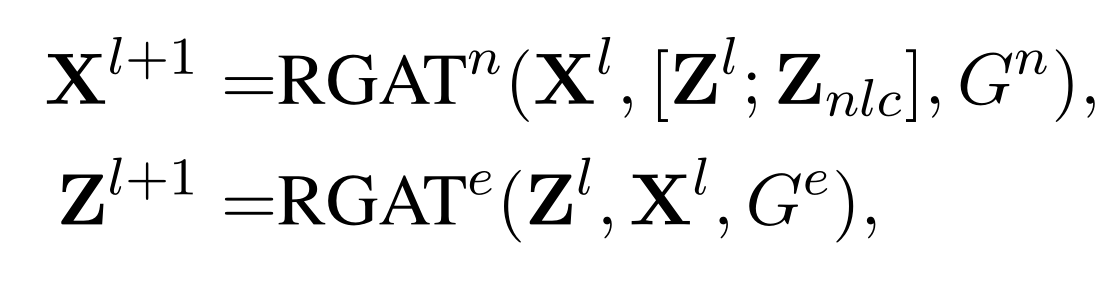
- 其中,$\mathbb{Z}_{nlc}$ 代表 original graph $G^{n}$ 的非局部边特征。
- 用上面公式可以看出,计算 original graph $G^{n}$ 的表示 $\mathbb{X}^{l}\in \mathbb{R}^{|V^{n}|\times d}$ 时会考虑局部和非局部关系;而在计算 line graph $G^{e}$ 的表示 $\mathbb{Z}^{l}\in \mathbb{R}^{|V^{e}|\times d}$ 时只考虑局部关系。
3.2.1 RGAT for the Original Graph
这一部分的作用是在计算节点的表示时增加邻居节点以及对应边的信息。
给定 original graph $G^{n}$ ,第 $l$ 层的输出 $x_{i}^{l+1}$ 的计算方式如下:
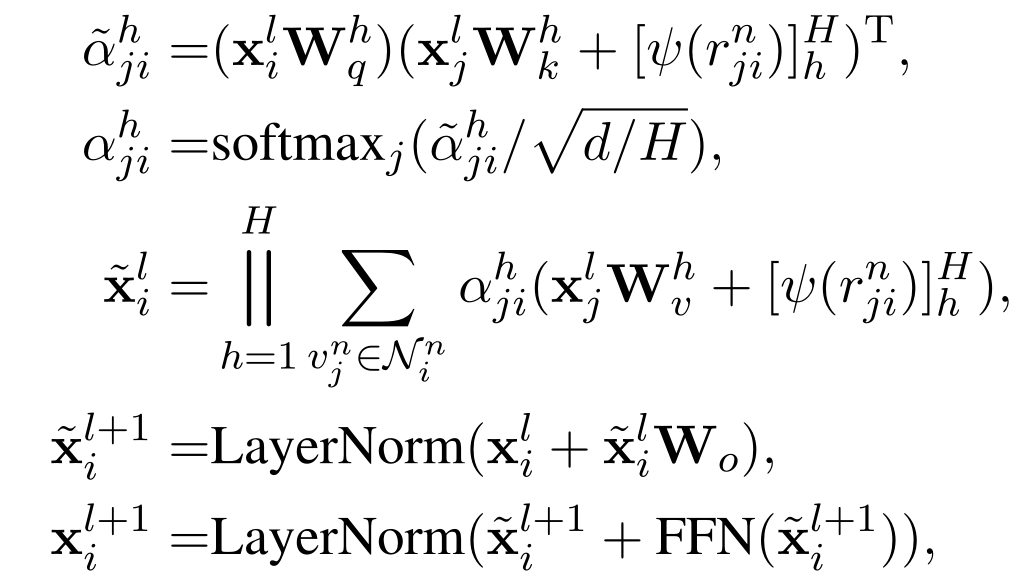
- ∣∣ 表示拼接操作,H是head 的数量,FFN()代表 feedforward neural network。
- $N_i^n$ 代表节点 $v_{i}^{n}$ 的 receptive field(感受野,应该是指跟 $i$ 节点相连的节点)
- $\psi(r^n_{ij})$会返回一个表示 $r_{ji}^{n}$ 的 $d$ 维向量(这个向量代表了 line graph $G^{e}$ 中的一个节点,因为 $G^{e}$ 中的节点是 $G^{n}$ 中的边)
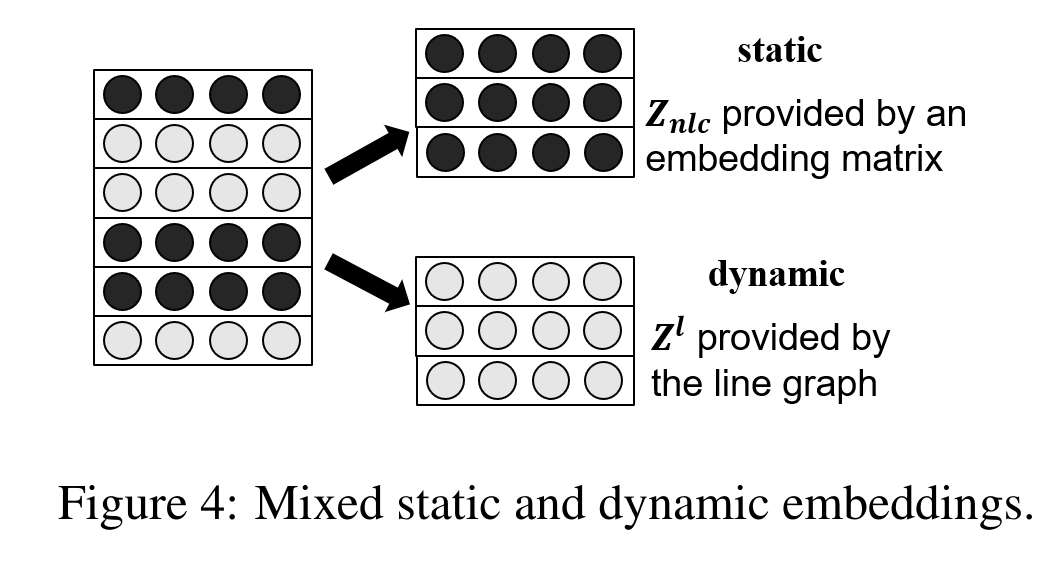
- $[.]_h^H$ 操作首先将向量平均分割为 H个部分并返回第h个分区,由于Line Graph的构建只利用了1阶连接关系,对于节点图中的高阶邻域,论文采取静态动态混合特征或多头多视图拼接的方法,将更远的节点及其边类型引入到节点图中对节点特征的更新中,这些包含远距离信息的边特征不会迭代更新,仅仅使用静态参数初始化。
Mixed Static and Dynamic Embeddings (混合静态和动态嵌入)
- 如果 $r_{ji}^{n}$ 是一个局部关系(一跳邻居),$\psi (r_{ji}^{n})$ 会从 line graph $G^{e}$ 中返回对应节点的 embedding $z_{f(j,i)}^{l}$。
- 否则,$\psi (r_{ji}^{n})$ 会返回非局部关系矩阵 $\mathbb{Z}_{nlc}$ 中对应的向量。
- 邻居函数 $N_{i}^{n}$ 会返回节点 $v_{i}^{n}$ 的所有邻居节点的集合 $V^{n}$ ,这个集合在所有的head都是共享的。
Multi-head Multi-view Concatenation (多头多视图拼接)
- 将多头注意力模块分成两部分。
- 一半的 head 中,邻居函数 $N_{i}^{n}$ 会返回节点 $v_{i}^{n}$ 的一跳邻居的集合。在这种方法中,$\psi (r_{ji}^{n})$ 会按照从第 $l$ 层获取的 $Z^{l}$ 中取得对应节点的特征 $z_{f(j,i)}^{l}$(在这一部分,每个节点只接受相邻的节点信息)
- 另外一半的 head 中,每个节点都可以接触到局部和非局部的邻居,$\psi (.)$会从嵌入矩阵 $\mathbb{Z}_{nlc}\cup \mathbb{Z}^{0}$ 中获取静态的特征embedding。
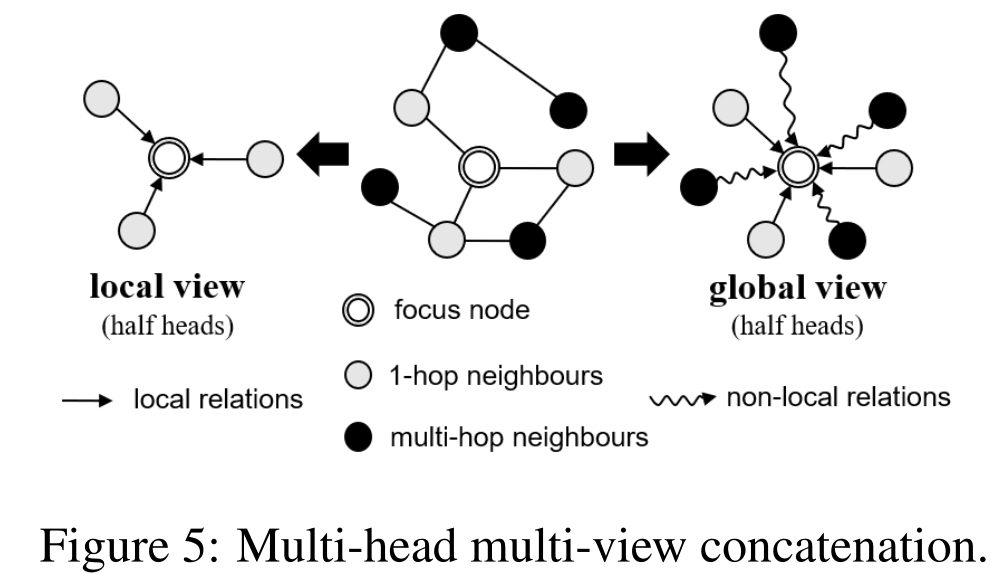
RGAT模块 对 局部 和 非局部 关系的处理是不同的,相对来说,对局部边特征的处理更仔细。
3.2.2 RGAT for the Line Graph
这一部分的作用是在计算边的表示时加入边的两端的节点信息以及相邻边的信息。
计算方式跟上面类似,这里不再细说
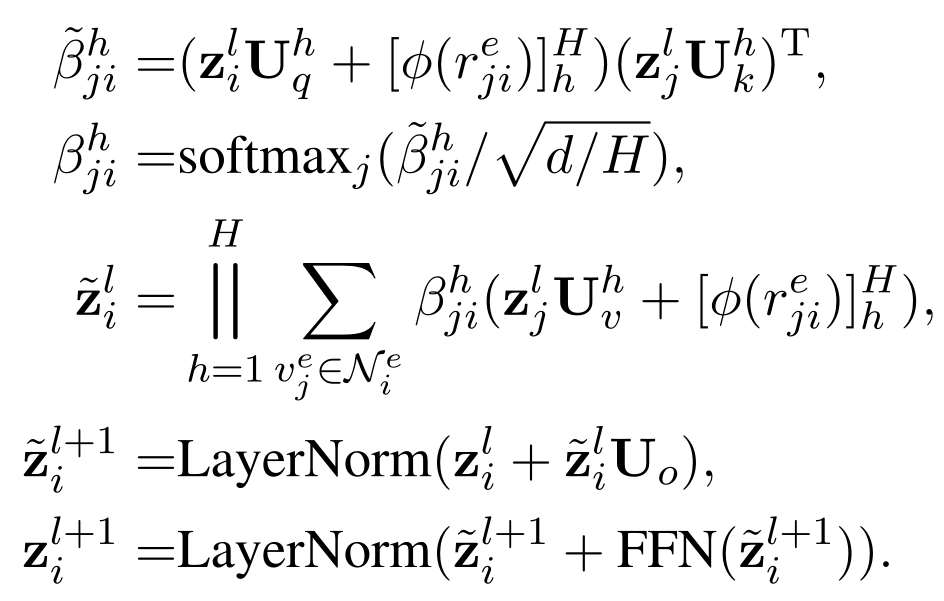
- $\psi (r_{ji}^{e})$ 返回 $G^{e}$ 中边 $r_{ji}^{e}$ 的特征向量,即返回 $G^{e}$ 中节点 $v^{e}_{i}$ 的对应于 $G^{n}$ 中的有向边的起始节点的 embeddings(举个例子,在下图中,$\phi(r_{e1 e2}^{e}$) 会返回 original graph 中两个圆圈的那个节点的 embeddings )
- 因为我们只在 line graph 中考虑局部信息,所以 $N_{i}^{e}$ 只包含 1跳邻居。
- 还有另外的一点需要注意,在这一部分,边的特征 $r_{ji}^{e}$ 被放在了 attention 的 query 部分而不是 key 部分,因为计算attention分数 $\tilde{\beta}_{ji}^{h}$ 时,跟起始节点 $j$ 是无关的。
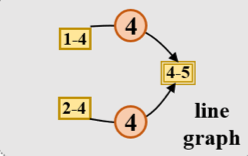
因为在attention中,算的是Q对K的相似度,如果放在key部分,则算的是起始节点 $j$ 对目标节点 $i$ 的相似度,但是在 line graph 中,如下图,(1-4,4-5)和(2-4,4-5)中间的边都表示原图中的4号节点,如果不换位置,则算的是1-4以及2-4对4-5的相似度,但是不管相似度哪个大,都是表示4号节点;再举个现实生活中的例子,两个男生追一个女生,哪个男生能追到女生并不是看哪个男生更喜欢女生,而是看女生更喜欢哪个男生。
3.3 Graph Output Module
该模块包括两个任务:一个用于 text-to-SQL 的 decoder,另一个用于执行称为 graph pruning(图剪枝)的辅助任务。
我们使用下标表示具有特定类型的 node embeddings 集合,例如, $X_{q}$ 表示所有 question 的 node embeddings 的矩阵。
3.3.1 Text-to-SQL Decoder
Decoder部分采用的是与RATSQL一致的grammar-based syntactic neural decoder来首先生成AST,然后再由AST语法树生成SQL语句。
3.3.2 Graph Prunning
一个强大的编码器应该将不相关的 schema items(模式项目) 与目标查询中使用的 golden schema items(正确的schema items) 区分开来(意思是把SQL查询中没有用到的items排除)。
在 图6 中,面向问题的模式子图(在阴影区域的上方)可以很容易地被提取出来。意图(要select的) c2 和约束(限制select的) c5 通常在问题中被明确提及,通过 attention机制 或 schema linking(模式链接) 确定。连接节点如t1、c3、c4、t2可以通过模式图的 1跳 连接来推断,形成一个连接的组件
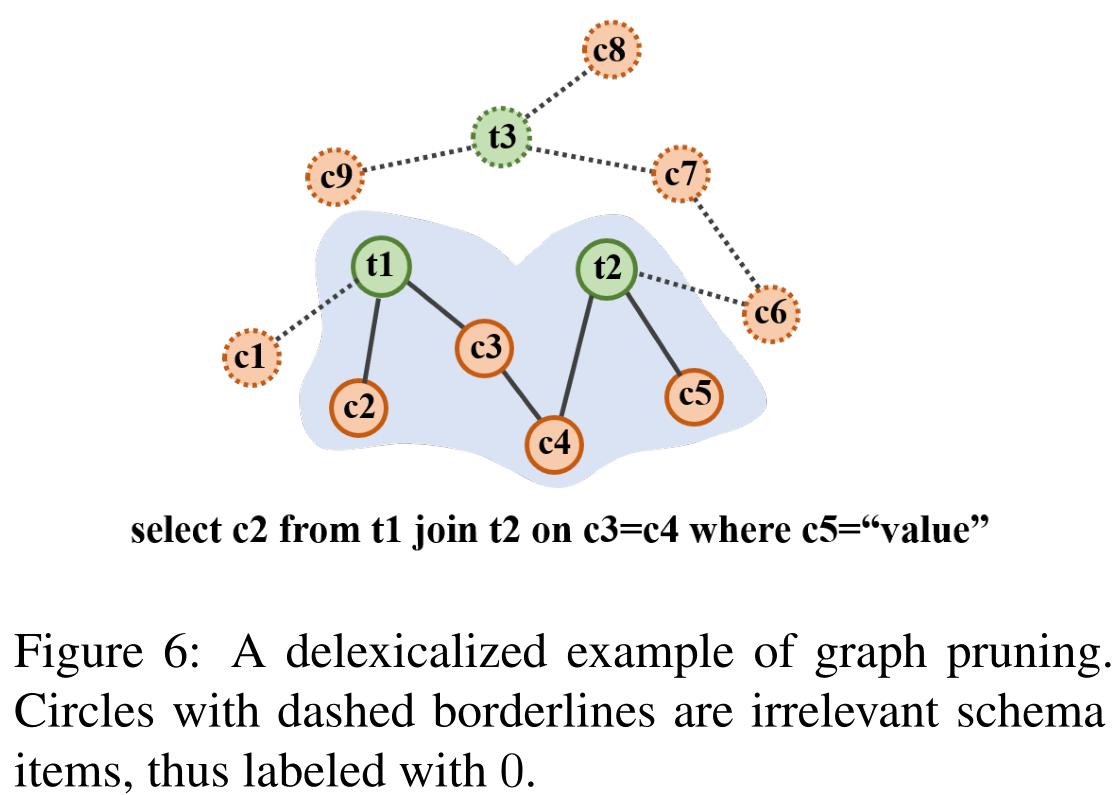
为了引入这种归纳性偏见,我们设计了一个辅助任务,根据schema node与问题的相关性和模式图的稀疏结构来决定对schema node进行分类。
首先,我们用 question 的 node embeddings $X_{q}$ 以及 schema 的 node embeddings $s_{i}$ 来计算两者的 attention , 目的是用来获取 context vector $\tilde{x}_{s_{i}}$。
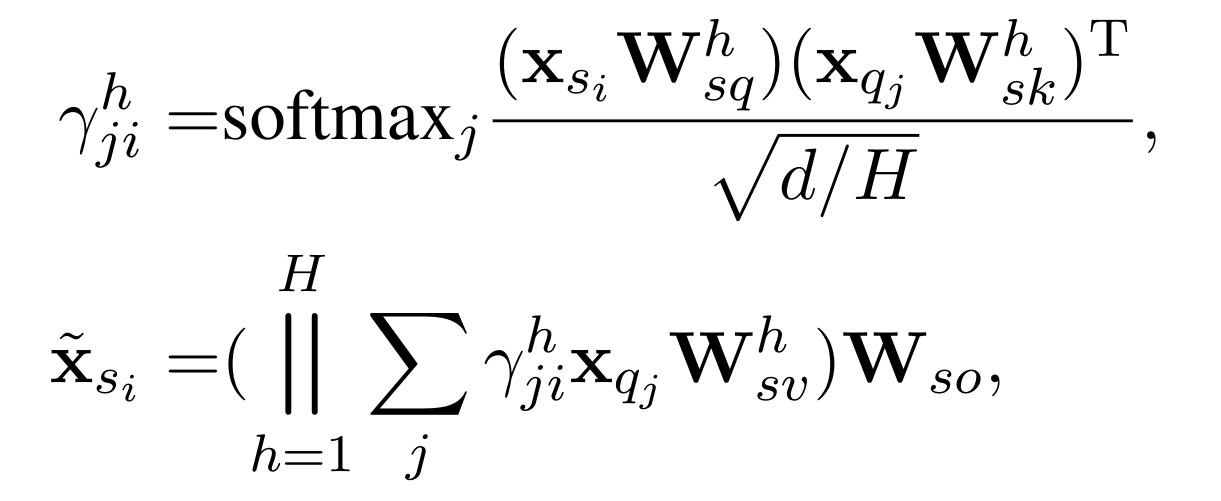
然后,使用 biaffine binary classifier(二元二进制分类器) 来确定 context vector $\tilde{x}_{s_{i}}$ 和 schema 的 node embeddings $s_{i}$ 是否是相互关联的。
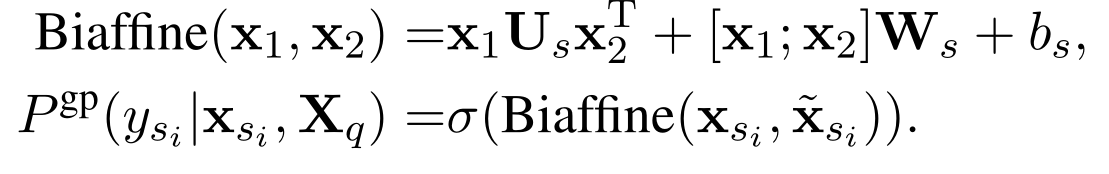
如果 schema 的 node embeddings $s_{i}$ 出现在目标SQL语句中,schema item 的 label $y_{s_{i}}^{g}$ 会是 1,使用交叉熵来计算 loss。
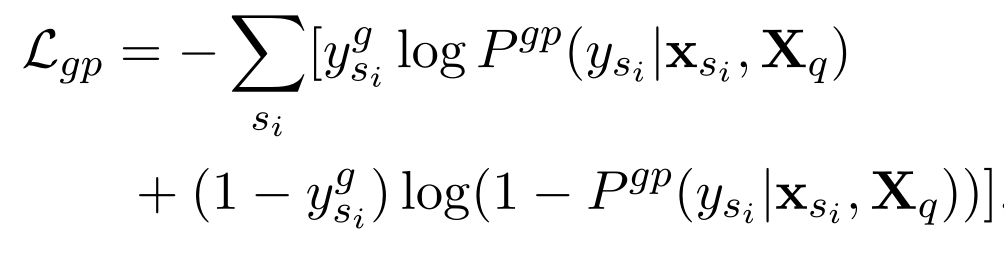
这个任务和主任务一同进行多任务学习,对提升主任务效果比较大。
实验
主要结果
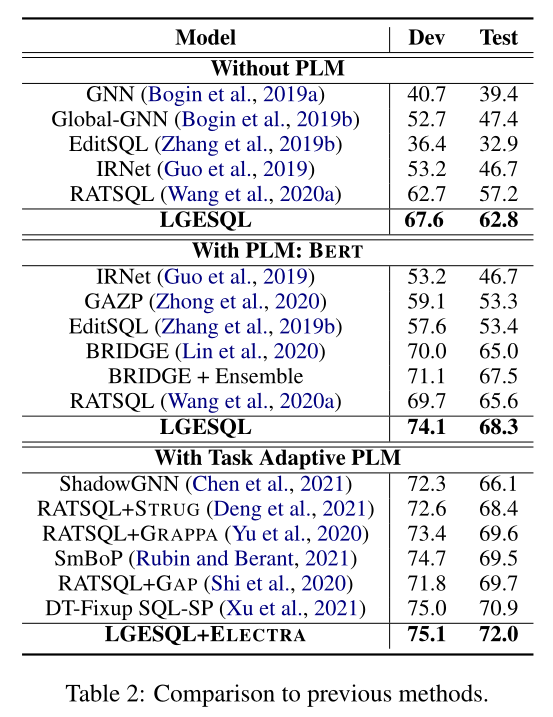
实验结果见上图,可以看到无论是使用PLM还是Glove,模型都取得了领先于之前最好的模型的表现。在各个分组的性能如下:
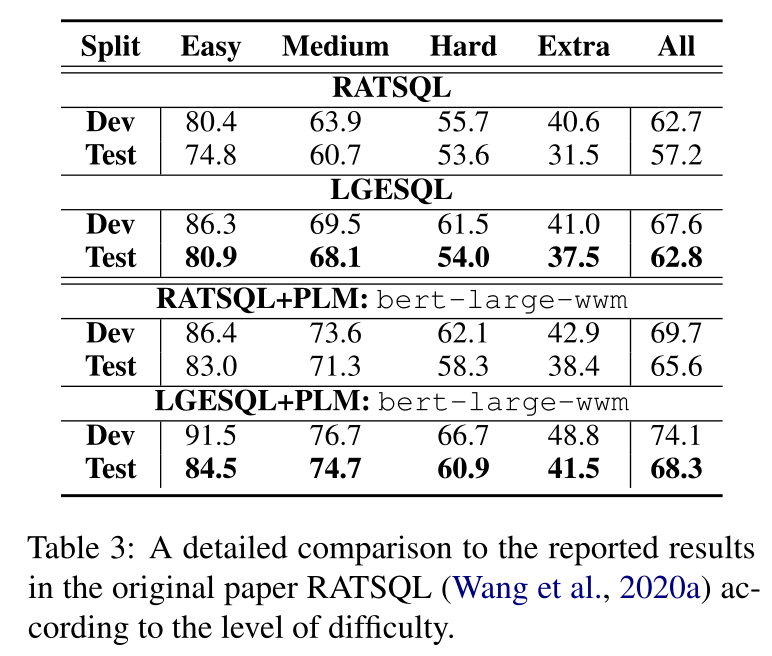
消融实验
LGESQL不同的组件的实验表现
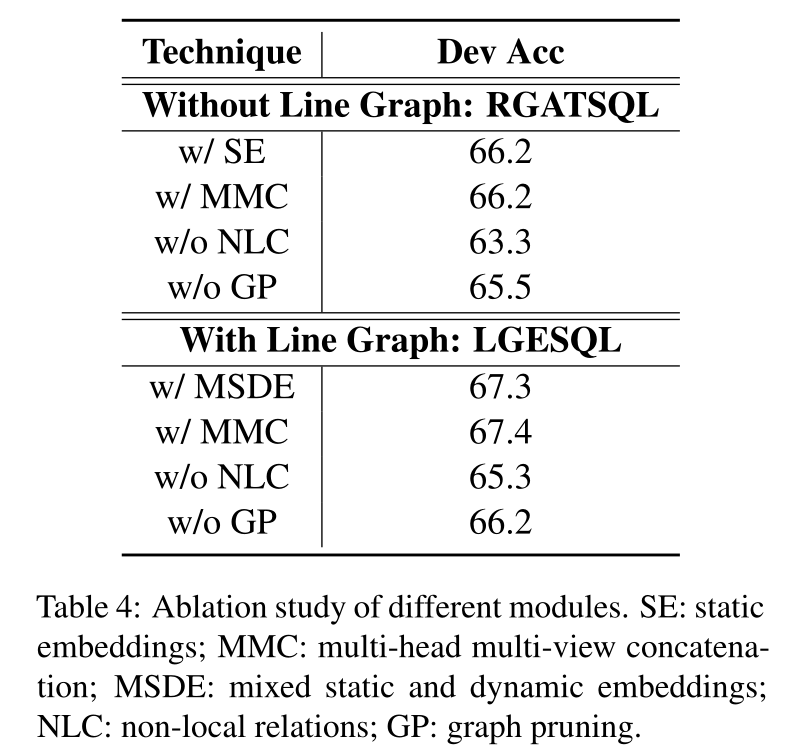
可以看到使用Line graph比不使用性能普遍高出1个百分点。而且Non-local relation是比较重要的。同时,多任务学习的Graph pruning模块也对最后结果有着不错的促进作用。
预训练模型的影响
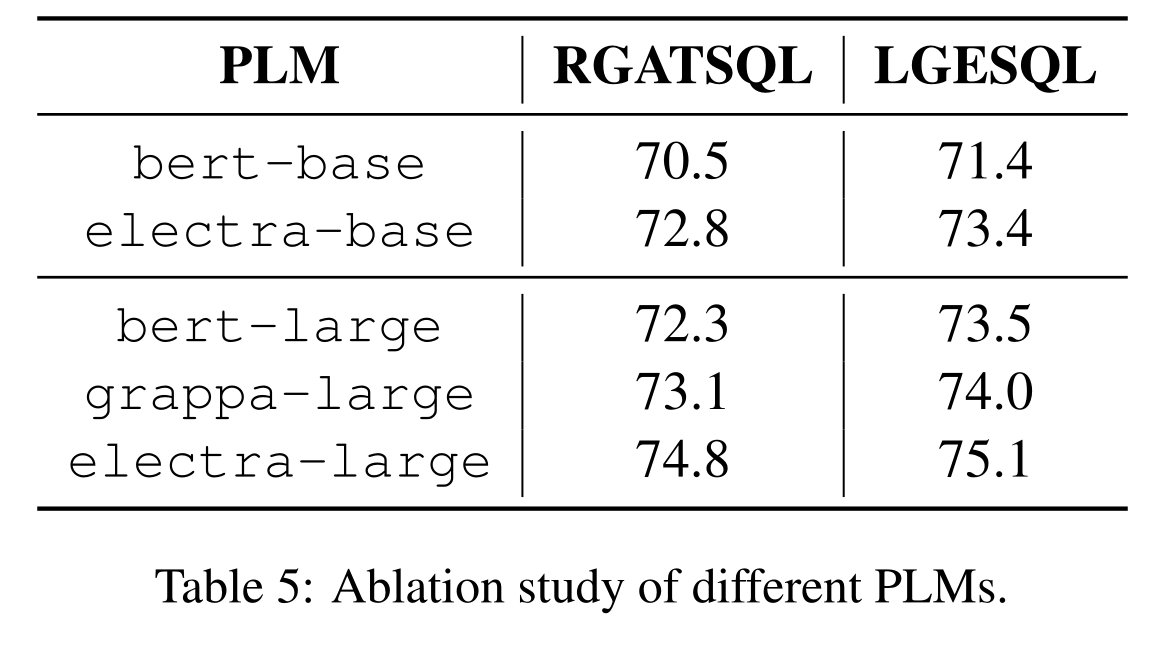
实验显示使用ELECTRA比BERT的效果要好。
案例研究

结论
在本工作中,我们利用Line graph来更新异质图中的边特征,用于Text-to-SQL的任务。通过对Line graph中的结构连接的迭代,局部边可以结合多跳关系特征并捕获重要的meta-path。通过进一步集成非本地关系,编码器可以从多个视图学习,并使用快捷方式关注远程节点。在未来,我们将研究更多有用的meta-path,并探索更有效的方法来处理不同的基于meta-path的邻居。
本文的贡献在于提出了利用对偶图来获取边的局部信息
附录
局部和非局部关系
实验中用到的所有局部关系如下:
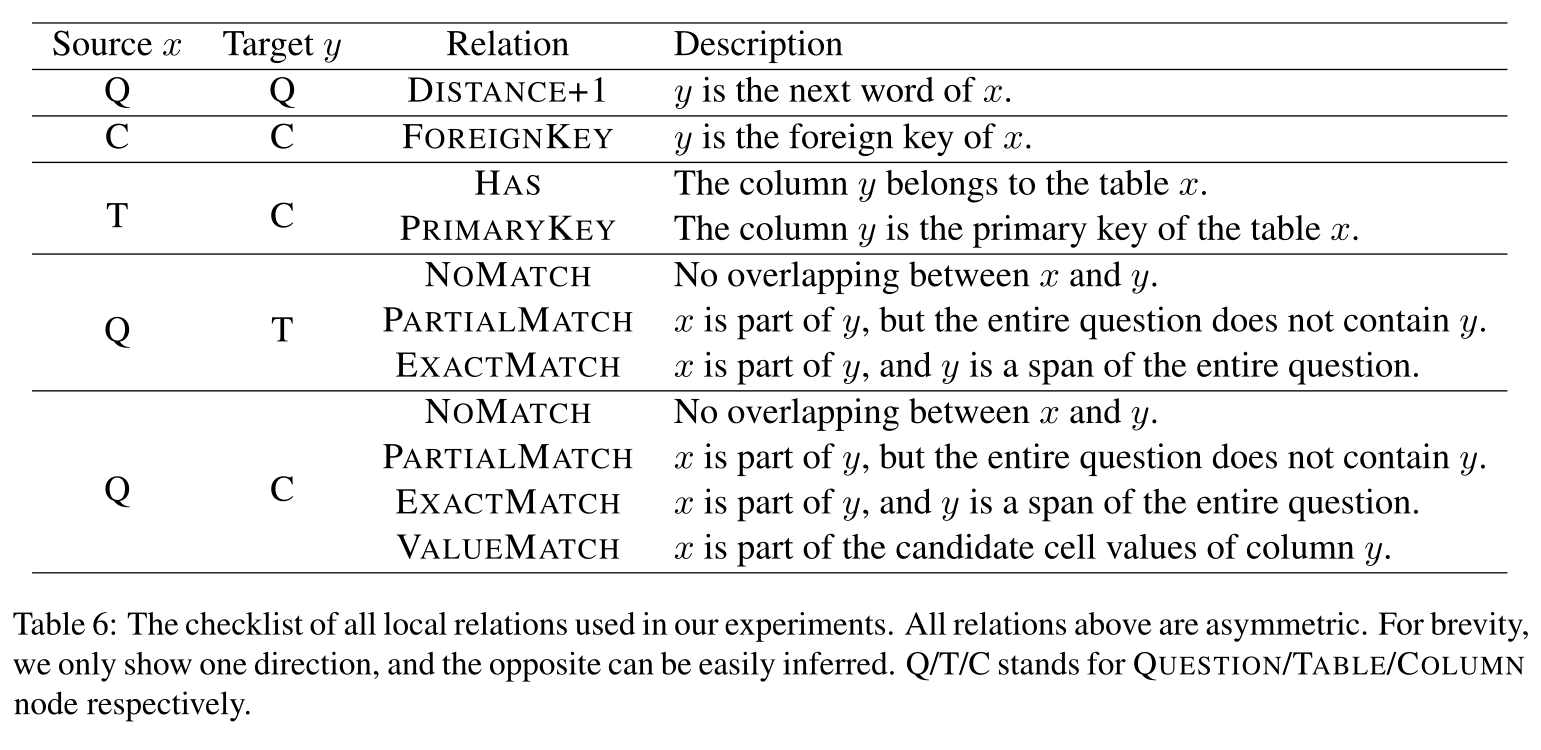
其中作者保留了NO-MATCH关系。
Text-to-SQL Decoder的细节
ASDL Grammar
所使用的ASDL语法如下

Decoder架构
Decoder中使用了一种新型的LSTM叫ON-LSTM,可以将结构信息考虑在内,详情参考ICLR 2019最佳论文 | ON-LSTM:用有序神经元表达层次结构。
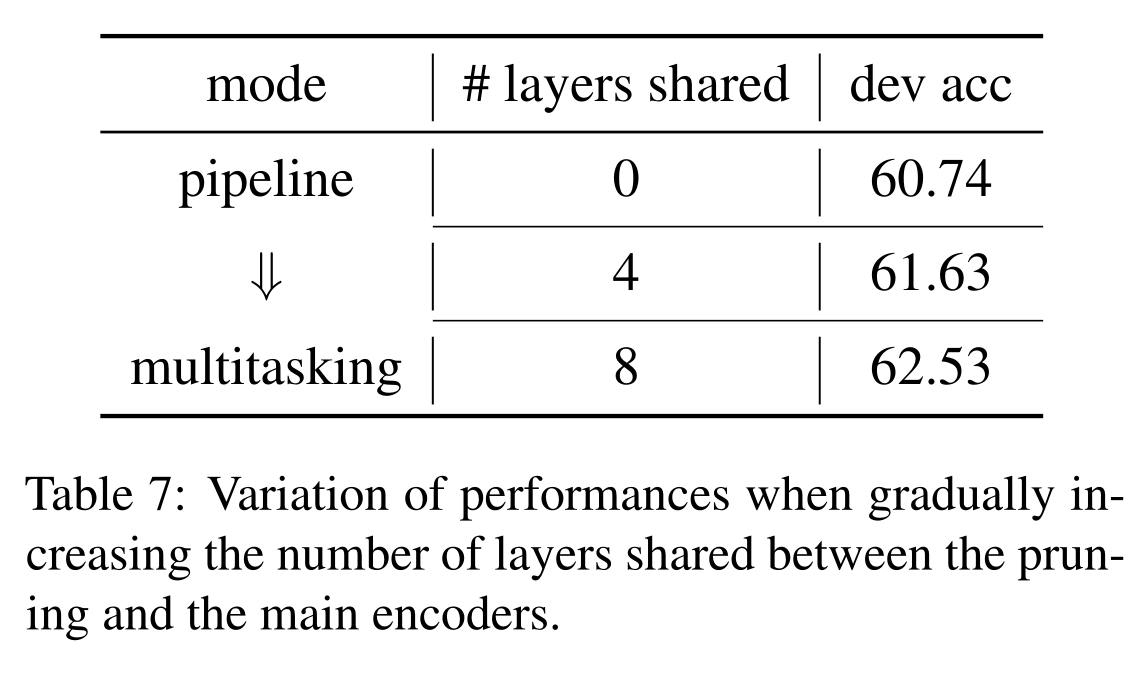
Graph pruning
这里作者做了一个实验,比较共享多少层给两个任务效果最好,结果发现直接多任务学习即共享所有层效果最佳。
参考
- LGESQL: Line Graph Enhanced Text-to-SQL Model with Mixed Local and Non-Local Relations
- LGESQL: Line Graph Enhanced Text-to-SQL Model with Mixed Local and Non-Local Relations 论文笔记_weixin_43829169的博客-CSDN博客
- 论文笔记:LGESQL: Line Graph Enhanced Text-to-SQL Model with Mixed Local and Non-Local Relations_11好好学习,天天向上的博客-CSDN博客
